In the realm of SQL databases, indexes play a crucial role in enhancing query performance. An index in SQL is akin to an index in a book; it allows the database engine to find data quickly without scanning the entire table. By creating indexes, we can significantly reduce the time it takes to retrieve rows, especially in large datasets. This blog will delve into the 6 various types of indexes in SQL, their characteristics, pros and cons.
>> Read more: Database Scaling Explained: A Guide to Efficient Growth
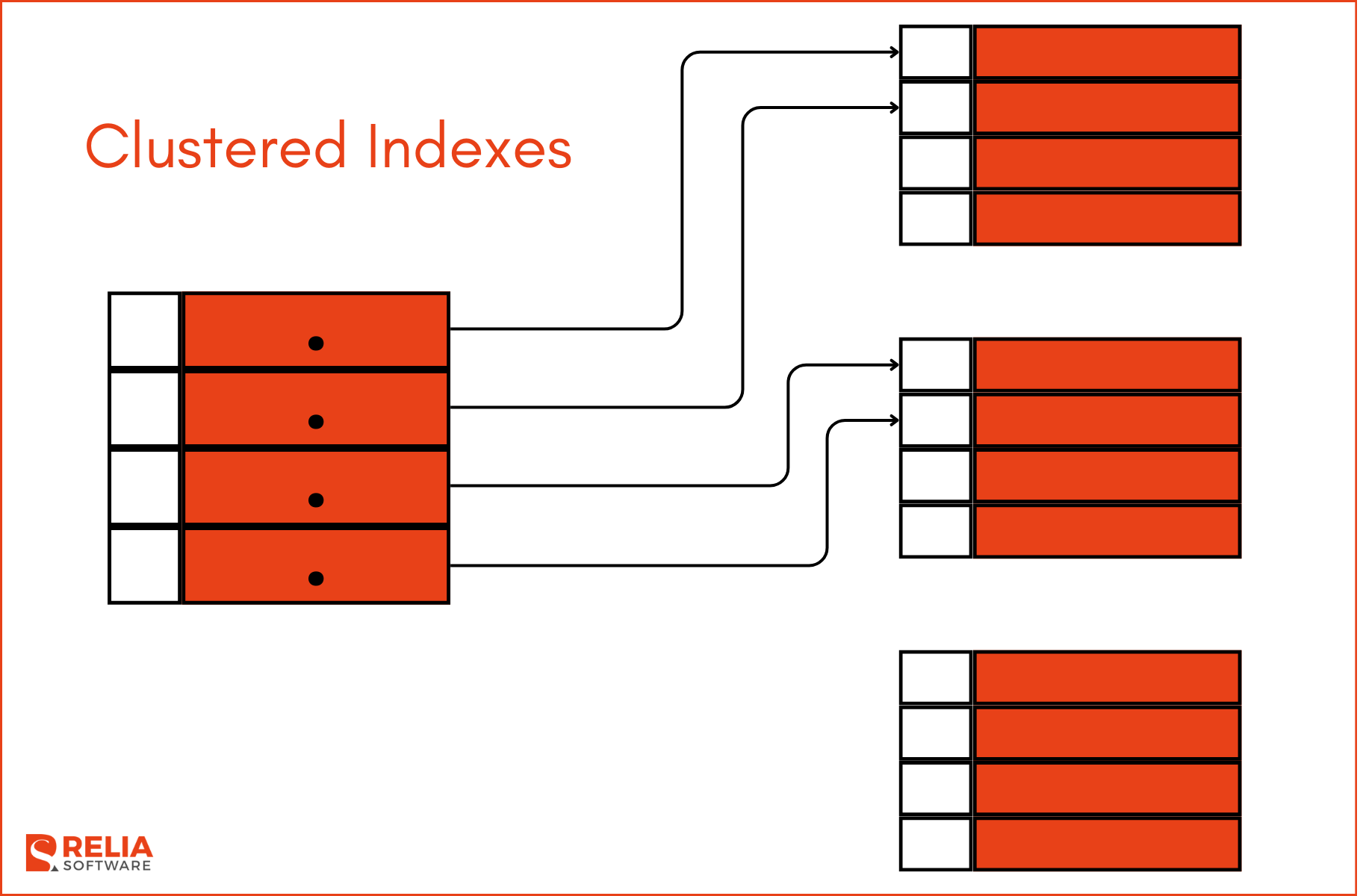
Clustered Indexes
A clustered index sorts and stores the data rows of the table based on the key values. There can only be one clustered index per table because the table rows themselves can only be arranged in a single sort order.
Characteristics
- The data in the table is physically rearranged to match the index:
When you create a clustered index, the rows in the table are physically sorted and stored in the order of the index key. This means that the actual data is stored in the leaf nodes of the index, making the table data and the index indistinguishable.
For example, if you create a clustered index on the EmployeeID column of an Employees table, the rows will be stored in the ascending order of EmployeeID.
- The clustered index key is typically the primary key of the database table:
Since a clustered index dictates the physical order of the data, it’s most efficient to use primary key columns that uniquely identifies each row. However, it’s not mandatory to use the primary key as the clustered index key. You can choose any column or combination of columns, but it’s best practice to use a unique, not null column.
For instance, while EmployeeID might be a natural choice for the clustered index, you could also use a unique column like SocialSecurityNumber if it better suits your query patterns. A database administrator should evaluate this decision carefully as part of broader indexing strategies.
Advantages
- Efficient for range queries:
Clustered indexes are particularly efficient for range-based queries. Because the data is physically stored in the order of the index, retrieving rows that fall within a specific range is much faster. This makes clustered indexes ideal for queries that filter results based on a range of values.
For example, querying for all employees hired within a certain date range can be done quickly if there is a clustered index on the HireDate column.
- Faster data retrieval for queries that require sorted data:
Queries that require data to be sorted such as those with ORDER BY clauses can benefit greatly from clustered indexes. Since the data is already sorted in the order of the index, the database engine doesn’t need to perform additional sorting operations, leading to faster query execution.
For instance, when querying for a list of employees ordered by LastName, a clustered index on LastName will make the retrieval much faster.
Disadvantages
- Slower performance for insert, update, and delete operations as the physical order of rows needs to be maintained:
Maintaining the physical order of rows according to the clustered index can introduce overhead during insert, update, and delete operations. When inserting a new row, the database might need to rearrange existing rows to maintain the order, which can slow down the operation.
Similarly, updating a key column that is part of the clustered index can require moving the row to maintain order, and deleting a row might leave gaps that need to be managed.
For example, inserting a new employee into the Employees table with a clustered index on EmployeeID might require shifting rows if the new ID is in the middle of the existing range.
- Only one clustered index per table:
Since the data can only be physically stored in one order, each table can have only one clustered index. This limitation requires careful consideration of which column to use for the clustered index to maximize query performance.
Choosing the wrong column for the clustered index can lead to suboptimal performance. For example, if most queries filter by LastName but the clustered index is on EmployeeID, the benefit of the clustered index might not be fully realized.
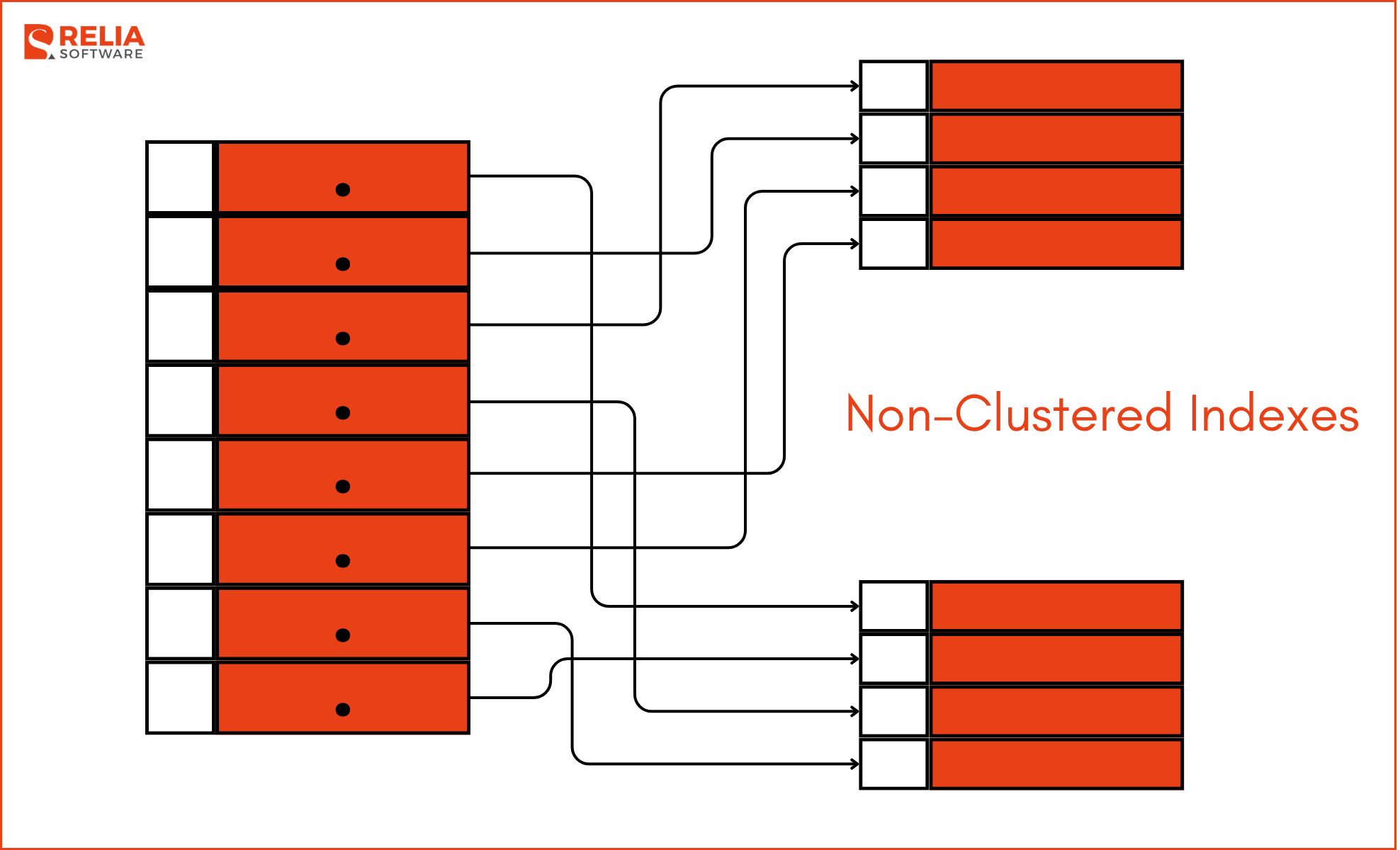
Non-Clustered Indexes
A non-clustered index, on the other hand, creates a separate structure that points to the actual data rows. Multiple non-clustered indexes can be created on a single table, providing flexibility in optimizing query performance for various columns.
Characteristics
- The data rows are not physically sorted to match the index:
Unlike clustered indexes, non-clustered indexes do not change the physical order of the data within the table. Instead, they create a logical order for the index, which contains the indexed columns and pointers to the actual data rows.
For example, if you create a non-clustered index on the LastName column of an Employees table, the index will store the LastName values in sorted order along with pointers to the corresponding rows in the table.
- Contains pointers to the actual data rows:
A non-clustered index includes the indexed column values and a row locator or pointer that maps to the actual data rows in the table. The row locator can be a row ID, primary key, or clustered index key.
For instance, if the Employees table has a clustered index on EmployeeID and a non-clustered index on LastName, the non-clustered index will have entries for LastName with pointers to the EmployeeID values, which can then be used to quickly locate the actual rows.
Advantages
- Faster retrieval of data for queries involving columns other than the primary key:
Non-clustered indexes significantly improve the performance of queries that filter or sort data based on columns other than the primary key or clustered index key. They provide a quick lookup mechanism for these columns without requiring a full table scan.
For example, a non-clustered index on the LastName column allows efficient retrieval of employees based on their last names, which is useful for queries like SELECT * FROM Employees WHERE LastName = 'Smith'.
- Multiple non-clustered indexes can be created per table:
You can create multiple non-clustered indexes on different columns of a table, enabling efficient query performance for various access patterns. This flexibility allows you to optimize for a wide range of queries.
For instance, an Employees table could have non-clustered indexes on LastName, DepartmentID, and HireDate, each improving the performance of different queries.
Disadvantages
- Takes up additional storage space:
Non-clustered indexes require additional storage space to maintain the index structure. The storage overhead can be significant, especially for large tables with multiple non-clustered indexes.
For example, each non-clustered index on the Employees table requires space to store the indexed column values and pointers, which adds to the overall storage requirements of the database.
- Can slow down data modification operations due to the need to update the index:
Insert, update, and delete operations on the table can become slower with non-clustered indexes because each modification may require corresponding updates to the indexes. The database must maintain the index structure to ensure consistency, which introduces overhead.
For instance, inserting a new employee into the Employees table necessitates updating all non-clustered indexes to include the new row, and deleting an employee requires removing the corresponding entries from the indexes.
Unique Indexes
A unique index ensures that the values in the indexed column(s) are unique across the table, which helps maintain data integrity. Unique indexes are critical in enforcing uniqueness constraints in databases, ensuring that no duplicate values exist in the indexed columns.
Characteristics
- Prevents duplicate values in the indexed column(s):
Unique indexes enforce uniqueness by preventing duplicate values in the specified columns. When a unique index is applied, the database engine checks the values being inserted or updated against the existing values in the index. If a duplicate value is detected, the operation is aborted, maintaining data integrity.
For example, if a unique index is created on the email column of a Users table, any attempt to insert or update a row with an existing email address will fail, ensuring that each email address is unique.
- Often used to enforce unique constraints on tables:
Unique indexes are typically used in conjunction with unique constraints to enforce rules at the database level. Unique constraints are logical rules applied to columns to ensure that all values in those columns are unique. Unique indexes support these constraints by providing the physical enforcement mechanism.
For instance, a unique constraint on the order_id column of an Orders table can be enforced with a unique index, ensuring that each order has a distinct identifier.
Use Cases
- Ensuring unique email addresses in a user table:
In applications where each user must have a unique email address, such as user registration systems, a unique index on the email column guarantees that no two users can register with the same email. This is essential for functionalities like login authentication, password recovery, and user communication.
Example SQL:
CREATE UNIQUE INDEX idx_unique_email ON Users (email);- Preventing duplicate order IDs in an order table:
Order management systems often require each order to have a unique identifier to track transactions, manage inventory, and handle customer queries. A unique index on the order_id column ensures that each order is uniquely identifiable, preventing issues with order processing and data analysis.
Example SQL:
CREATE UNIQUE INDEX idx_unique_order_id ON Orders (order_id);- Combining Multiple Columns:
Unique indexes can be created on a combination of columns to enforce uniqueness across multiple fields. This is useful in scenarios where a combination of values must be unique. For example, a unique index on both first_name and last_name can ensure that no two records have the same combination of names.
Example SQL:
CREATE UNIQUE INDEX idx_unique_name ON Employees (first_name, last_name);- Improving Query Performance:
Besides enforcing data integrity, unique indexes can improve query performance. When a unique index is used in a query, the database engine can quickly locate the specific row because the index guarantees that there is only one matching entry.
For example, a query to retrieve user details by email can leverage the unique index on the email column for fast lookup:
SELECT * FROM Users WHERE email = 'example@example.com';- Ensuring Unique Product SKUs:
In inventory management systems, each product must have a unique SKU (Stock Keeping Unit) to accurately track inventory levels and sales. A unique index on the sku column of the Products table ensures that each product has a distinct identifier, preventing errors in inventory management.
Example SQL:
CREATE UNIQUE INDEX idx_unique_sku ON Products (sku);Advantages
- Data Integrity: Unique indexes help maintain data integrity by ensuring that values in the indexed columns are unique. This prevents data anomalies and ensures that each record is identifiable by its unique attributes.
- Efficient Data Retrieval: Unique indexes enhance query performance by providing a quick lookup mechanism for unique values. Queries that filter on unique columns can execute faster because the database engine knows that it will find at most one matching row.
Disadvantages
- Overhead on Data Modifications: Maintaining unique indexes adds overhead to insert, update, and delete operations. The database must check for uniqueness before performing these operations, which can slow down performance, especially for large tables with high write activity.
- Storage Requirements: Unique indexes require additional storage space to maintain the index structure. The storage overhead can be significant for tables with large numbers of unique indexes or high cardinality columns.
Full-Text Indexes
Full-text indexes are specialized indexes used for text-searching capabilities. They allow for efficient searching of large text columns and are useful for implementing search functionality in applications where textual data needs to be queried extensively.
Characteristics
- Optimized for searching text data:
Full-text indexes are specifically designed to handle large volumes of text data efficiently. Unlike standard indexes, which are suitable for exact matches and simple patterns, full-text indexes excel at searching for complex text patterns and phrases within large datasets.
For example, a full-text index on a ProductDescription column can quickly find all products containing specific keywords, regardless of their position within the text.
- Supports advanced search options like full-text search, prefix searches, and proximity searches:
Full-text indexes support various advanced search features, such as:
- Full-text search: Allows searching for words or phrases within text columns. This includes options for matching whole words, partial words, and synonyms.
- Prefix searches: Enables searching for words that start with a specific prefix, which is useful for auto-complete functionalities.
- Proximity searches: Allows searching for words that are within a certain distance from each other in the text, enabling more natural language queries.
For instance, a full-text index on an ArticleContent column can support queries like finding all articles that mention "database" within five words of "index".
Use Cases
- Implementing search functionality in content management systems:
Content management systems (CMS) often require robust search capabilities to help users find relevant articles, blog posts, or documentation. Full-text indexes enable efficient and accurate searching through large volumes of text content.
Example: In a CMS for a news website, a full-text index on the ArticleBody column allows users to search for news articles containing specific keywords or phrases quickly.
CREATE FULLTEXT INDEX ON Articles (ArticleBody);
SELECT * FROM Articles WHERE CONTAINS(ArticleBody, 'database');- Searching product descriptions in e-commerce platforms:
E-commerce platforms need to provide effective search functionality to help customers find products based on descriptions, features, and specifications. Full-text indexes enhance the search experience by allowing users to perform detailed searches within product descriptions.
Example: In an e-commerce platform, a full-text index on the ProductDescription column enables customers to search for products that match detailed queries, such as "wireless noise-canceling headphones."
CREATE FULLTEXT INDEX ON Products (ProductDescription);
SELECT * FROM Products WHERE CONTAINS(ProductDescription, 'wireless AND noise-canceling');- Ranking and Relevance:
Full-text indexes often include features for ranking and relevance scoring. When performing a full-text search, results can be ranked based on how closely they match the search criteria, ensuring that the most relevant results appear first.
For example, in a search for "database indexing techniques," articles that mention both "database" and "indexing" frequently and in close proximity will rank higher in the search results.
- Support for Natural Language Queries:
Full-text indexes can support natural language processing (NLP) techniques, allowing users to perform more intuitive searches. This includes handling synonyms, stemming (e.g., searching for "running" also finds "run"), and stop words (common words like "and" or "the").
For example, a full-text search for "running shoes" can also return results for "run shoes" or "jogging footwear."
- Integration with Search Engines:
Full-text indexing can be integrated with search engines and external search services to provide even more advanced search capabilities. This integration can enhance the search experience by leveraging the power of specialized search technologies.
Example: Integrating SQL Server's full-text search with an external search engine like Elasticsearch for large-scale search applications.
Advantages
- Efficient Text Searches: Full-text indexes dramatically improve the efficiency of text searches, making it possible to quickly find relevant information within large text columns. This efficiency is crucial for applications that rely heavily on text search functionality.
- Advanced Search Capabilities: The support for advanced search options, such as proximity and prefix searches, allows for more sophisticated and accurate search queries, enhancing the user experience in search-heavy applications.
Disadvantages
- Resource Intensive: Full-text indexing can be resource-intensive, requiring significant CPU and memory resources for indexing large volumes of text data. This can impact the overall performance of the database server, especially during indexing operations.
- Maintenance Overhead: Full-text indexes require regular maintenance to ensure optimal performance. This includes updating the index as the underlying data changes and periodically rebuilding the index to address fragmentation and improve search efficiency.
Composite Indexes
Composite indexes are indexes on multiple columns. They are useful for queries that filter on multiple columns or when columns are often used together in WHERE clauses.
Characteristics
- Indexes Multiple Columns:
Composite indexes include two or more columns in the index key. This allows the database engine to use the index for queries that filter or sort by any combination of the indexed columns.
For example, a composite index on LastName and FirstName in an Employees table can efficiently support queries filtering by last name, first name, or both.
- Column Order Matters:
The order of the columns in a composite index is important. Queries benefit most when the indexed columns are used in the same order as defined in the index. The database can efficiently use the index if the query's WHERE clause matches the leading columns of the index.
For instance, an index on (LastName, FirstName) is most effective for queries that filter by LastName first, and then by FirstName.
Advantages
- Optimizes Multi-Column Queries:
Composite indexes are particularly effective for queries that involve multiple columns in the WHERE clause, improving performance by reducing the need for full table scans.
Example: A query like SELECT * FROM Employees WHERE LastName = 'Smith' AND FirstName = 'John' benefits significantly from a composite index on (LastName, FirstName).
- Reduces the Number of Indexes Needed:
By indexing multiple columns together, composite indexes can reduce the need for multiple single-column indexes, thus saving storage space and potentially improving performance for a broader range of queries.
Disadvantages
- Larger Index Size:
Composite indexes can be larger than single-column indexes, as they store information for multiple columns. This can increase the storage requirements and impact the performance of data modification operations.
Example: An index on (ProductCategory, ProductName) in a Products table will be larger than separate indexes on ProductCategory and ProductName.
- Complexity in Index Management:
Managing and maintaining composite indexes can be more complex, as they need to be carefully designed to match the most common query patterns. Changes in query patterns may require re-evaluating and updating the index structure.
Use Cases
Filtering by Multiple Columns:
Composite indexes are ideal for tables where queries frequently filter by multiple columns, such as searching for employees by department and job title, or filtering products by category and price range.
Example SQL:
CREATE INDEX idx_employee_department_job ON Employees (Department, JobTitle);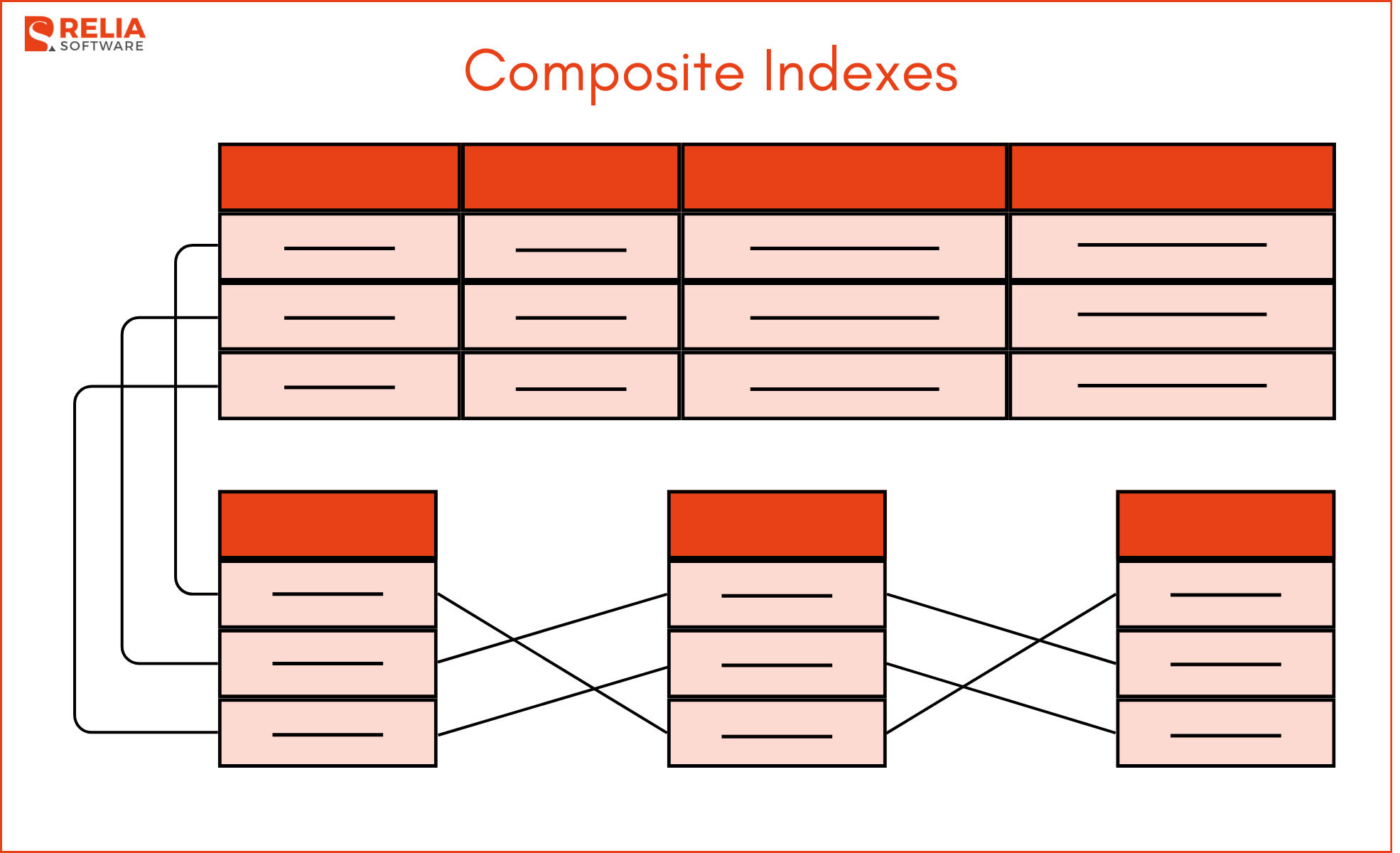
Filtered Indexes
Filtered indexes are non-clustered indexes that include rows that meet a specific condition. They are beneficial for indexing a subset of rows in a large table.
Characteristics
- Indexes a Subset of Rows:
Filtered indexes are created with a WHERE clause that specifies the condition for including rows in the index. This allows the index to be smaller and more efficient by only including relevant rows.
For example, a filtered index on the IsActive column of a Users table can index only the rows where IsActive = 1.
- Selective Indexing:
By indexing only a subset of the data, filtered indexes can provide significant performance improvements for queries that target specific conditions, without the overhead of indexing the entire table.
Example: An index on Orders table for rows where OrderStatus = 'Pending' is much smaller and faster than indexing all orders.
Advantages
- Improved Performance for Specific Queries:
Filtered indexes can dramatically improve the performance of queries that frequently filter by the indexed condition, as the index is smaller and more focused on the relevant subset of data.
Example: A query like SELECT * FROM Orders WHERE OrderStatus = 'Pending' benefits from a filtered index on OrderStatus.
- Reduced Index Maintenance:
Since filtered indexes are smaller, they require less maintenance and storage space. This can result in faster index rebuilds and updates, especially in tables with a large number of rows.
Example: Maintaining an index on active users (IsActive = 1) in a Users table is more efficient than indexing all users.
Disadvantages
- Limited Use Cases:
Filtered indexes are only beneficial for queries that match the filtering condition. Queries that do not match the condition cannot use the filtered index, which limits its applicability.
Example: A filtered index on OrderStatus = 'Pending' is not useful for queries that need to retrieve completed orders.
- Complex Index Design:
Designing effective filtered indexes requires a deep understanding of the query patterns and data distribution. Improperly designed filtered indexes can lead to suboptimal performance and increased complexity.
Example: Creating a filtered index on a column with low selectivity or frequent updates may not yield significant performance benefits.
Use Cases
- Indexing Frequently Queried Subsets:
Filtered indexes are ideal for scenarios where a specific subset of data is queried frequently, such as active users, pending orders, or recent transactions.
Example SQL:
CREATE INDEX idx_active_users ON Users (UserID) WHERE IsActive = 1;- Optimizing Sparse Columns:
Filtered indexes can optimize performance for queries on sparse columns, where only a small number of rows have non-null or specific values. This is useful for columns with optional data or flags.
Example: Indexing non-null values in a DiscountCode column of an Orders table:
CREATE INDEX idx_orders_with_discount ON Orders (OrderID) WHERE DiscountCode IS NOT NULL;How to Choose the Right Index?
Selecting the appropriate type of index for your SQL database depends on various factors, including query patterns, table structure, and specific application needs.
First, identify your query patterns by analyzing the most common and performance-critical queries to determine which columns are frequently used in WHERE clauses, joins, and sorting operations. For instance, if queries often filter by OrderDate, OrderStatus, and CustomerID, these columns are candidates for indexing.
Next, consider the table structure, including the size of the table and the nature of the data. Clustered indexes are beneficial for large tables with range queries, such as a Sales table frequently queried by date ranges.
Evaluate the impact on performance by weighing the benefits of faster read operations against the potential slowdowns in write operations. For example, while a clustered index on OrderDate in an Orders table speeds up read operations, it may slow down inserts and updates due to the need to maintain the physical order of rows.
Use composite indexes wisely, especially if queries often filter on multiple columns. Composite indexes, such as one on (CustomerID, OrderDate), can be more efficient than multiple single-column indexes, reducing the need for multiple index lookups. Ensure the leading columns in composite indexes have high selectivity for optimal performance.
Leverage unique and filtered indexes to enforce data integrity and optimize specific queries. Unique indexes, like on Email in a Users table, prevent duplicate entries and ensure data uniqueness. Filtered indexes are beneficial for queries involving a subset of rows, such as an index on OrderStatus for only 'Pending' orders, which improves performance without indexing the entire table. For example, creating a filtered index in SQL might look like this:
CREATE INDEX idx_pending_orders ON Orders (OrderID) WHERE OrderStatus = 'Pending';By following this approach, you can strategically select indexes that enhance query performance, maintain data integrity, and balance the trade-offs between read and write operations in your SQL database.
>> Read more:
- What is a Graph Database? Benefits, Use Cases & Examples
- Vector Database vs Graph Database: Which One Is Better?
Conclusion
Indexes are powerful tools for optimizing query performance in SQL databases. By understanding the different types of indexes and their use cases, you can make informed decisions to improve the efficiency of your database operations. Remember, while indexes can significantly speed up data retrieval, they also require careful management to maintain optimal performance.
Feel free to experiment with different index types and monitor their impact on your database. With the right indexing strategy, you can ensure that your SQL queries run swiftly and efficiently.
Below is the table summarizing key features of the 6 aforementioned types of indexes in SQL.
| Index Type | Definition | Best Use Cases | Performance Impact |
|---|---|---|---|
| Clustered | Alters physical order of data to match the index | Large tables with range queries | Faster reads, slower writes |
| Non-Clustered | Separate structure with pointers to data | Exact match queries | Moderate read speed improvement |
| Unique | Ensures all values in the indexed column are unique | Columns that require unique values | Data integrity, moderate read speed |
| Composite | Indexes multiple columns together | Queries filtering on multiple columns | Efficient multi-column filtering |
| Full-Text | Specialized index for fast text searches | Large text fields, search optimization | High read performance for text searches |
| Filtered | Applies index to a subset of rows | Queries involving specific subsets of data | High read performance for specific queries |
>>> Follow and Contact Relia Software for more information!

- coding
- development