
Increased computational power, in-memory computing, and agreed-upon standards brought the concept of leveraging databases to map relationships digitally from academia to commercial and enterprise computing. Therefore, graph databases have been created to illustrate the data clearly. Family trees are simple graph database examples.
So what is the graph database? How it can be used? And how does it differ from other database types? Let's discover the answers to these questions in the article below.
Graph Databases Definition
A graph database is a specialized platform for creating and manipulating associative and contextual data. The graph itself consists of nodes, edges, and characteristics that work together to enable users to express and store data in ways that relational databases cannot.
A relationship is the central idea of a graph database system. Relationships are considered first-class citizens, which means that they can do anything that other elements can. Data is linked together in a graph to form a collection of nodes and edges, with edges representing the relationship between nodes. However, it's not universally applied across all graph database systems. While some treat relationships on par with nodes, others might have a slight hierarchy.
Relationships enable data within the system to be linked directly. Relationships in a graph database are fast to query because they are kept in a consistent format. You may also visualize them, which makes them ideal for extracting insights from highly interrelated data.
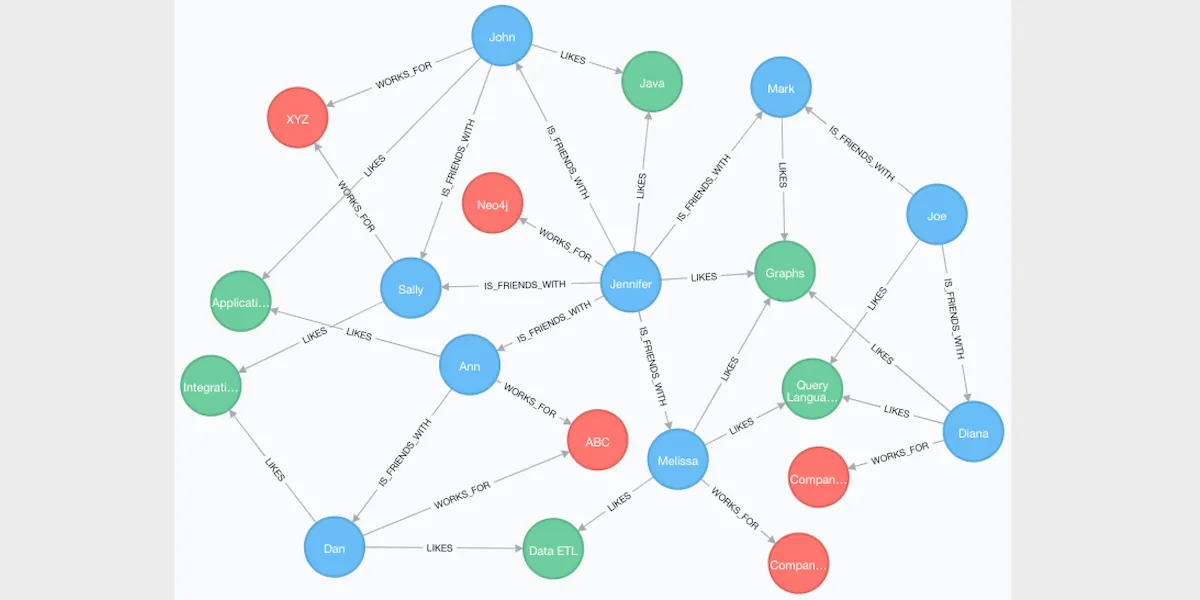
Main Components of Graph Databases
As was already said, graph databases let people show data as a graph. Nodes, edges, and properties are the three most important parts of this type of data modeling.
Nodes
A node is a way to describe an object or instance. In a conceptual sense, a node is like a row in a relational database, and it acts like a point in a graph. Adding a name to each member of a group is all it takes to group a node. Nodes can also hold various data types like strings, numbers, booleans, etc.
Edges
The lines that connect nodes in a graph are called edges. There is always a start node, an end node, a type, and a path in a relationship. They describe parent-child relationships, acts, ownership, and other things that make up the data patterns.
Edges can also have properties associated with them, further describing the relationship. These properties can define the type of relationship (e.g., "friends with", "knows", "bought"), the strength of the connection, or any other relevant data.
Properties
To put it simply, properties are the data that is linked to nodes. Properties allow you to store specific attributes of the entity represented by the node or the nature of the connection represented by the edge.
You can describe each node with its own set of properties or characteristics. There are times when edges also have qualities. The same thing can also be called a property graph.
Types of Graph Databases
Property Graphs
Property graphs show how different pieces of data are related to each other and let you ask for and analyze data based on these connections. A property graph has points (vertices) that can hold detailed information about a subject and lines (edges) that show how the points are connected. There may be traits, or properties, that are linked to the vertices and edges.
In this case, a property graph shows a group of coworkers and the connections between them. Property graphs typically use native graph storage for efficient retrieval of connected data. They are useful in many fields because they can be used in many ways. They are used in banking, manufacturing, public safety, retail, and many more.
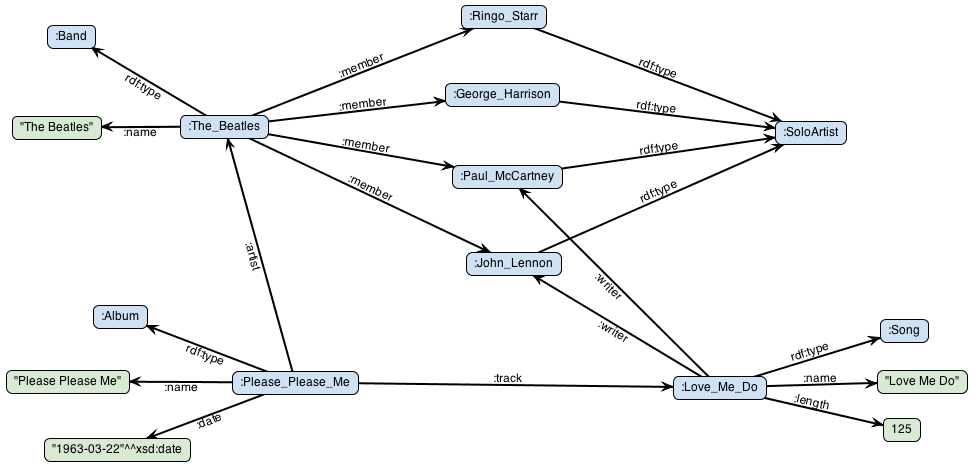
RDF Graphs
RDF graphs are suitable for representing complicated metadata and master data because they follow W3C standards for representing statements. Their uses include linked data, data integration, and knowledge graphs. They can represent sophisticated domain concepts or give rich data semantics and inference. However, while RDF graphs are good for data integration, they are not ideal for complex graph analytics due to their rigid structure.
An RDF triple represents a sentence's subject, predicate, and object as two vertices connected by an edge. Each vertex and edge has a unique URI. The RDF paradigm allows data exchange by publishing data in a standard format with well-defined semantics. Government statistics agencies, pharmaceutical businesses, and healthcare organizations use RDF graphs.
Benefits of Using Graph Databases
Many advantages over relational databases make graph databases useful tools for managing complex, interrelated data. We discuss several significant benefits:
Effective Relationship Management
Graph databases excel in representing data point relationships, unlike relational databases for structured data. Their structure is based on nodes (entities) and edges. Graph databases can effectively navigate complicated networks and answer related data queries by explicitly storing relationships. Consider a social network with members as nodes and friendships as edges. Finding a user's buddy or a friend is easy in a graph database.
Faster, More Flexible Queries
In graph databases, traversing relationships is faster than joining tables. Queries can directly follow explicitly defined connections to retrieve data faster. Graph databases are flexible enough for ad-hoc queries that uncover unexpected data associations. This makes them perfect for data exploration and finding hidden patterns.
Large Dataset Scalability
Graph databases scale well as data amounts expand. They provide horizontal scaling, so more servers may be added to manage data growth. This distributed technique makes big data applications possible with smooth performance even with enormous datasets.
What Are Graph Databases’ Use Cases?
Due to the ability to describe and analyze complicated relationships, graph databases are useful in many fields. Let's look at some cool ways this could be used:
Social Network Analysis
Graph systems are very important for social media sites like Facebook and LinkedIn to understand how users are connected and interact with each other. By modeling users as nodes and links (like friendships and follows) as edges, they can quickly suggest friends, look at how users behave, and find topics that are popular in their network.
Fraud Detection and Security
To fight fraud, financial institutions use graph databases to find hidden links between deals. They can use accounts, transactions, and people as nodes and look at the connections between them to find patterns that seem fishy. In real-time, this lets them find fraud groups, money laundering operations, and other security threats.
Recommendation Systems
Graph databases are used to customize the experiences of users on e-commerce sites and video services. They can make user profiles by looking at what people have bought, browsed, and connected with on social networks. Then, they can suggest films, music, or goods that match each person's tastes. This personalized method makes users more interested and increases sales.
Knowledge Graphs and Machine Learning
Graph libraries are very important for creating knowledge graphs, which are huge networks of connected things and ideas. These knowledge graphs are the building blocks for apps that use AI and machine learning. Graph databases give robots the power to do things like natural language processing and automated reasoning by helping them understand how entities are related to each other.
Examples of Graph Databases
Neo4j
Neo4j is one of the world's premier graph databases, allowing users to identify patterns and insights across billions of data connections. Neo4j is a highly scalable NoSQL open-source database built in Java. For additional information, check out our NoSQL concepts course.
The key features include:
-
Allows for intuitive and flexible data modeling, making it easier to navigate complex data interactions.
-
Optimises data retrieval and graph traversal, resulting in faster and more efficient processing of huge datasets and complicated queries.
-
Atomicity, consistency, isolation, and durability (ACID) compliant transactions ensure dependable data processing while maintaining data accuracy and trustworthiness throughout all transactions.
-
The Cypher graph query language simplifies the extraction of meaningful insights from interconnected data. It is both powerful and user-friendly.
-
Our high-performance native API development enables efficient database interactions, making it ideal for low latency and high throughput applications.
-
Enables the seamless execution of Cypher queries from apps, resulting in more dynamic and engaging user experiences.
-
Provides development flexibility by supporting drivers for a variety of programming languages, including C#, Go, Java, JavaScript, and Python, allowing for seamless integration into a wide range of technological stacks.

Amazon Neptune
Amazon Neptune, a fast, reliable, and fully managed graph database service, makes densely connected data applications easy to design and run. Neptune is built on a powerful graph database engine. This engine maintains billions of relationships and queries the graph with millisecond latency.
Key features:
-
Supports open graph APIs like Gremlin and openCypher for property graphs and SPARQL for RDF graphs, allowing developers to use common query languages to interface with the database.
-
Secures data and ensures regulatory compliance by establishing strong security measures, preserving data, and ensuring database integrity and confidentiality.
-
Simplifies user experience by managing database processes like hardware provisioning, software patching, setup, and configuration, letting developers focus on app development.
-
Automated backups improve data durability and facilitate disaster recovery by handling backup procedures automatically, protecting data from accidental loss, and enabling restoration.

ArangoDB/ OrientDB
Another common choice is OrientDB, which is also called ArangoDB.
You can get ArangoDB for free and use it as a NoSQL graph database system. It has a single database core and a single query language called ArangoDB Query Language (AQL). It supports three data models: graphs, JSON documents, and key/value. The tool is mostly a query language that lets you combine different ways of accessing data into a single query.
It is free and written in Java, and OrientDB is a NoSQL database management system. OrientDB is a multi-model database like ArangoDB. It allows graphs, JSON documents, key/value, and object models. However, relationships are managed like in graph databases, with direct links between records. The tool has a strong security profiling system that is based on users and roles. It also lets you query using Gremlin and SQL which has been expanded to allow graph traversal.

Graph Databases vs. Relational Databases
Similarities
Data Storage and Management
The main objective of both database formats is data storage and management. Structured environments help organize and access information. This lets businesses and organizations store and access massive datasets.
Data Manipulation
Both graph and relational databases allow data modification. Users can add, delete, and update database data. This flexibility ensures data is current and reflects changes.
Query Languages
Both database formats use query languages to obtain and alter data. SQL, a sophisticated language for structured data, dominates relational databases. Specialized languages like Cypher are used to navigate graph links in graph databases. Users can efficiently retrieve and analyze database data using these query languages.
Differences
Graph and relational databases differ in form and data relationships, although they share basic functions.
Data Model
The data model is key. Relational databases use rows and columns to organize data. Foreign keys link tables and establish data point relationships. This organized technique handles predictable, well-defined data well.
Nodes (entities) and edges (connections between nodes) form a versatile model in graph databases. Complex joins are unnecessary because structure relationships are fundamental. This makes graph databases great at representing complex data linkages.
Data Relationships
This data modeling difference greatly affects how each database handles relationships. Relational databases struggle with complex relationships, joining several tables. For complex connections with many data points, this method might be slow and difficult.
However, graph databases excel in intricate interactions. The structure explicitly defines connections, so queries can efficiently traverse them to retrieve data. They excel in social network analysis, fraud detection, and recommendation systems, where entity relationships are key.
Scalability
Scalability is another major distinction. Relational databases vertically scale by adding more powerful hardware to handle growing data volumes. This method works for smaller datasets but can be expensive and slow for large ones.
Graph databases scale horizontally well. This method lets you add new servers to the database system, dispersing workload and assuring smooth performance with rising datasets. This makes them ideal for big data applications with growing data quantities.
Querying
The way users query data also differs. SQL, a sophisticated language for structured data, dominates relational databases. SQL is flexible, but querying complicated relationships across numerous tables can be difficult.
Cypher is used in graph databases. These languages specialize in graph connection navigation. This lets users design more straightforward queries that effectively retrieve and analyze relationship-based data.
Here's a table summarizing the key points comparisons between these two types of databases:
|
Features |
Graph Databases |
Relational Databases |
|
Data Model |
Flexible (nodes, edges, properties) |
Structured (tables, rows, columns) |
|
Relationships |
Inherent to the structure (edges) |
Defined through foreign keys (joins) |
|
Querying Relationships |
Efficient (follows connections) |
Slow and complex (multiple joins) |
|
Scalability |
Horizontal scaling (strong) |
Vertical scaling (limited) |
|
Query Language |
Cypher (or similar, specialized for relationships) |
SQL (powerful but complex) |
Future of Graph Databases
Over the next ten years, graph databases will likely be very important in many different fields, such as machine learning, Bayesian analysis, data science, artificial intelligence, and helping to handle enterprise data and data exchange.
One of the most important changes this type of database will see is better data sharing. When it's easy to connect knowledge graphs, one database will be able to figure out that it needs data that it doesn't have and automatically get it from another knowledge graph. Federation's ability to do this means that it will probably help developers make blockchains that use the right metadata to verify events in smart contracts, banking, and finance.
Conclusion
This blog has answered the basic question “What is a Graph Database?” for you. Graph databases are specialized, one-use systems used to make and change data that is linked and contextual. You also learned that relational and graph databases certainly have the same job, which is to store data and show connections, but they do it in very different ways.
Follow us to be acknowledged about this topic deeper in the future!
>>> Follow and Contact Relia Software for more information!

- development