Streaming data use cases include growing data volumes and complicated interactions, making vector and graph databases difficult to use. Vector technology is being added to graph database platforms to help. However, there are differences between these two databases you must know to ensure using them in the right cases.
In this blog, we’ll explain vector and graph databases, compare their differences and similarities as well as show you a guide to choose the right approach for your case.
What is A Vector Database?
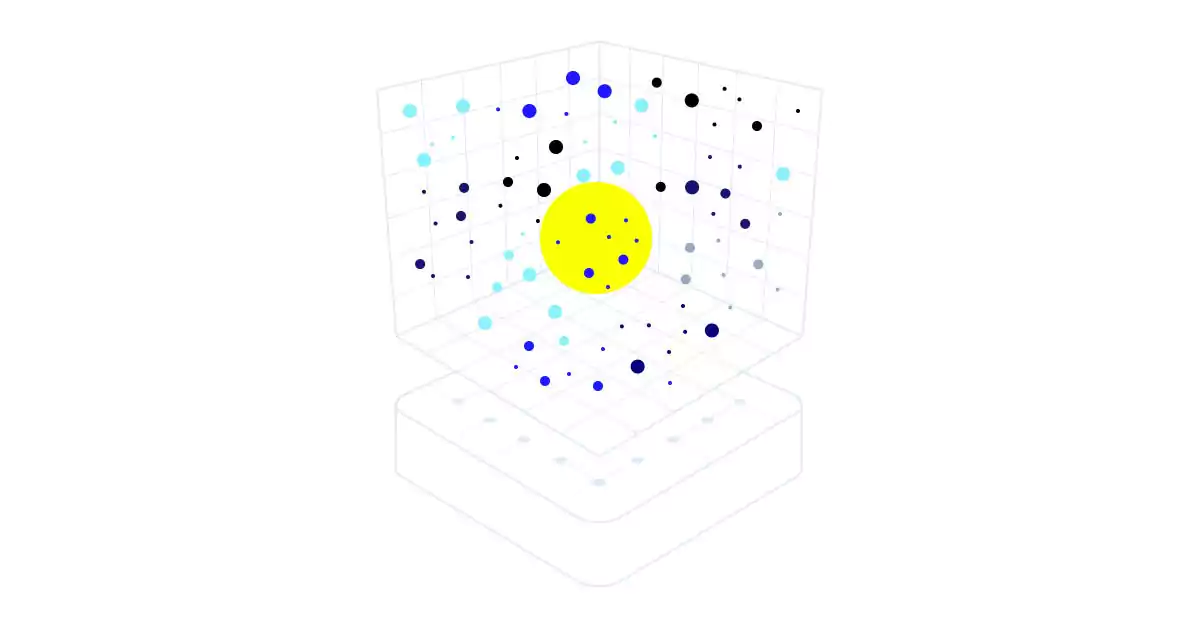
Vector databases organize data as points in a huge, multi-dimensional space instead of rows and columns. Data is represented as points, and their locations indicate their relative properties.
Data is stored as high-dimensional vectors, which numerically represent data features. Vectors express data by encoding and organizing it in multidimensional space. The closer the two points are in multidimensional space, the more similar their data.
This is why vector databases thrive in similarity search. Due to the vectors' similarity, you can quickly find data points that match your query vector. This makes them useful for several crucial applications:
-
Retrieve similar photos and documents using content, not keywords.
-
Recommend personalized products or information based on past interactions.
-
Find fraud data points or system faults.
-
Process high-dimensional data efficiently for text analysis, image classification, and NLP.
What is A Graph Database?
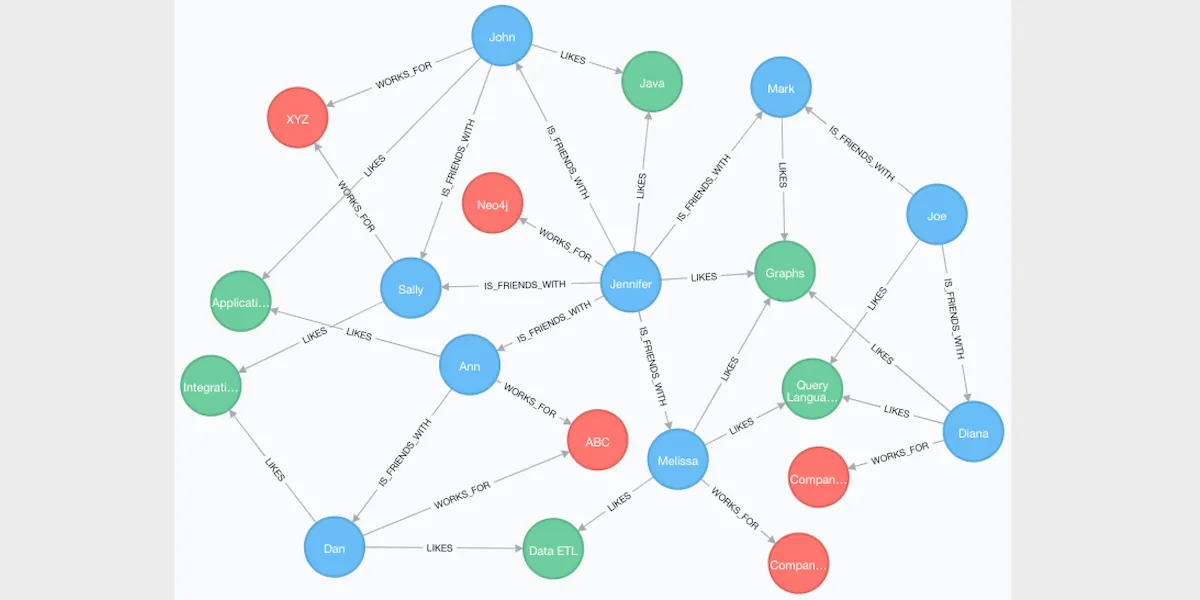
A graph database is an approach that uses graphs instead of tables or similarity groups like relational and vector databases. Nodes on the graph represent entities, while edges represent relationships. Like a mindmap, each node is a circle representing people, locations, or things, and the edges reflect their relationships.
Vector Database vs Graph Database: Key Differences
Comparing vector and graph databases requires understanding their differences in the data model, query capabilities, performance, scalability, and applications.
Data Model
Vector databases are designed to manage vector data, which are numbers representing objects in high-dimensional space. These databases are optimized for similarity search, allowing vector distance-based matching.
However, graph databases store and manage data as nodes and edges, representing entities and their relationships. This approach shows data points' interactions naturally, making complex relationships easy to visualize.
Query Capabilities
Vector databases prioritize vector similarity searches. They efficiently handle queries like nearest neighbor searches, identifying the database's closest vector to a query vector.
Advanced relationship-based queries in graph databases let users investigate node relationships. They excel at social and supply chain networks.
Performance Considerations
Vector databases shine in high-speed similarity search over big datasets since they are optimized for such operations. Their architecture is optimized to reduce data dimensionality and expedite query replies.
Meanwhile, graph databases can handle interconnected data. However, as the network grows in size and complexity, it can only function if optimized for certain queries.
Scalability
Scalability differs greatly between the two databases. With improved indexing and GPU acceleration, vector databases can more efficiently handle massive volumes of high-dimensional data. While scalable, graph databases require careful planning and resources to handle node and relationship growth and maintain performance.
Applications
Different applications suit different databases. Vector databases are utilized in recommendation systems, picture and voice recognition, and other AI-driven similarity-based applications. In contrast, social network research, financial network fraud detection, and complicated logistics routing challenges require graph databases to grasp relational contexts.
Understanding these essential differences will help users choose the right database type for their needs, ensuring efficient data processing.
Here is the table summarizing the distinctions of these two database visualizations.
|
Feature |
Vector Database |
Graph Database |
|
Data Model |
Objects in high-dimensional space |
Nodes and edges |
|
Query Capabilities |
Vector similarity searches |
Advanced relationship-based queries |
|
Performance Consideration |
High-speed similarity search over big datasets |
Interconnected data |
|
Scalability |
Massive volumes of high-dimensional data |
Node, relationship growth, and maintain performance |
|
Applications |
Recommendation systems. Picture and voice recognition. AI-driven similarity-based applications. |
Social network research. Financial network fraud detection. Complicated logistic. |
Similarities of Vector & Graph Database
Although vector and graph databases differ in data structure and query methods, they have certain important similarities that make them useful for complicated data:
-
NoSQL Flexibility: Vector and graph databases are NoSQL. They are schema-less or flexible, making them more adaptable to changing data structures than relational databases. Working with complex and dynamic data sets requires this flexibility.
-
Relationships: Both database types excel at representing and managing complicated data relationships. Vector and graph databases are used for similarity searches to find links or data point associations. They excel at social network analysis and fraud detection, where understanding relationships is crucial.
-
Advanced Analytics: Vector and graph databases handle advanced data analysis. Vector databases excel at similarity search and nearest neighbor identification, essential for recommendation systems and anomaly detection. In contrast, graph databases efficiently traverse and analyze connected data, allowing in-depth examination of complicated network linkages and patterns.
-
Big Data Compatibility: Both databases can manage enormous, complicated datasets due to their scalability and performance optimizations. Real-time analytics and large-scale machine learning solutions require this.
Steps To Choose Between Vector Database vs Graph Database
Step 1: Understand Your Data
First, understand your data well. This entails determining its format—numerical, textual, graphic, or a mix. Moreover, can it be conveyed well? Vector databases work well with multidimensional data. For social media and knowledge graph modeling, graph databases excel at describing data with natural links.
Step 2: Determine Key Use Cases
What jobs do you imagine your database doing? Do you prioritize similar data items (e.g., past purchases)? Vector databases excel at similarity searches, thus this fits. If you're interested in data linkages, such as social network hidden connections, a graph database may be better.
Step 3: Assess Query and Performance Needs
Explore your query needs after identifying use cases. Do you need frequent vector-based similarity searches, which vector databases excel at? Do you need graph databases' strength of traversing and analyzing links inside a network of entities? Understanding these query requirements will affect your choice.
Additionally, consider the performance needs. How important is query speed and efficiency for your app? Each database type's search complexity and data size performance effects must be understood.
Step 4: Evaluate Infrastructure and Scalability
Next, examine data scalability. Your data volume will expand how? Add more nodes to vector and graph databases to scale horizontally. Scaling a graph database with many connections is difficult. Finally, consider if either database type fits your data ecology. Make sure your team is comfortable maintaining and querying each database technology.
Step 5: Compare Prices
The next stage is to compare vector and graph database licensing prices and resource needs. Understanding the financial consequences of each choice will help you choose the most cost-effective project solution.
Step 6: Choose The Right Database Wisely
Following these procedures and considering your project goals will help you choose a vector database for similarity searches and high-dimensional data or a graph database for relationship and network research.

>> You may consider:
- Mastering Index in SQL to Improve Database Performance
- Understanding 6 Different Types of Indexes in SQL
- Database Scaling Explained: A Guide to Efficient Growth
Conclusion
Vector and graph databases are novel methods for big data exploration. However, choosing the proper model can be difficult. Carefully assess the above aspects and grasp each technology's strengths. You'll have a list of elements to help you choose the proper database model to maximize your data.
>>> Follow and Contact Relia Software for more information!

- development