
As your application grows in popularity, the demands on your database inevitably increase. You start experiencing slow loading times, frustrated users, and potential data bottlenecks. This is where database scaling comes into play. This blog will be your one-stop guide to navigating the world of database scaling. We'll break down the different techniques and strategies you can use to ensure your database keeps pace with your application's growth, all while maintaining optimal performance and a smooth user experience.
>> Read more:
- What is a Graph Database? Benefits, Use Cases & Examples
- Vector Database vs Graph Database: Which One Is Better?
- Mastering Index in SQL to Improve Database Performance
What is Database Scaling?
Database scaling refers to the process of modifying the size and capacity of a database system to handle an increased load of data and user requests. This process ensures that the database can maintain its performance and responsiveness as the demand grows.
Scaling can involve either increasing the processing power and storage capacity of the existing hardware (vertical scaling) or adding more servers to distribute the load (horizontal scaling). By implementing effective database scaling techniques, organizations can achieve better performance, reliability, and flexibility in their database systems, which are fundamental for supporting modern, data-driven applications.
2 Types of Database Scaling
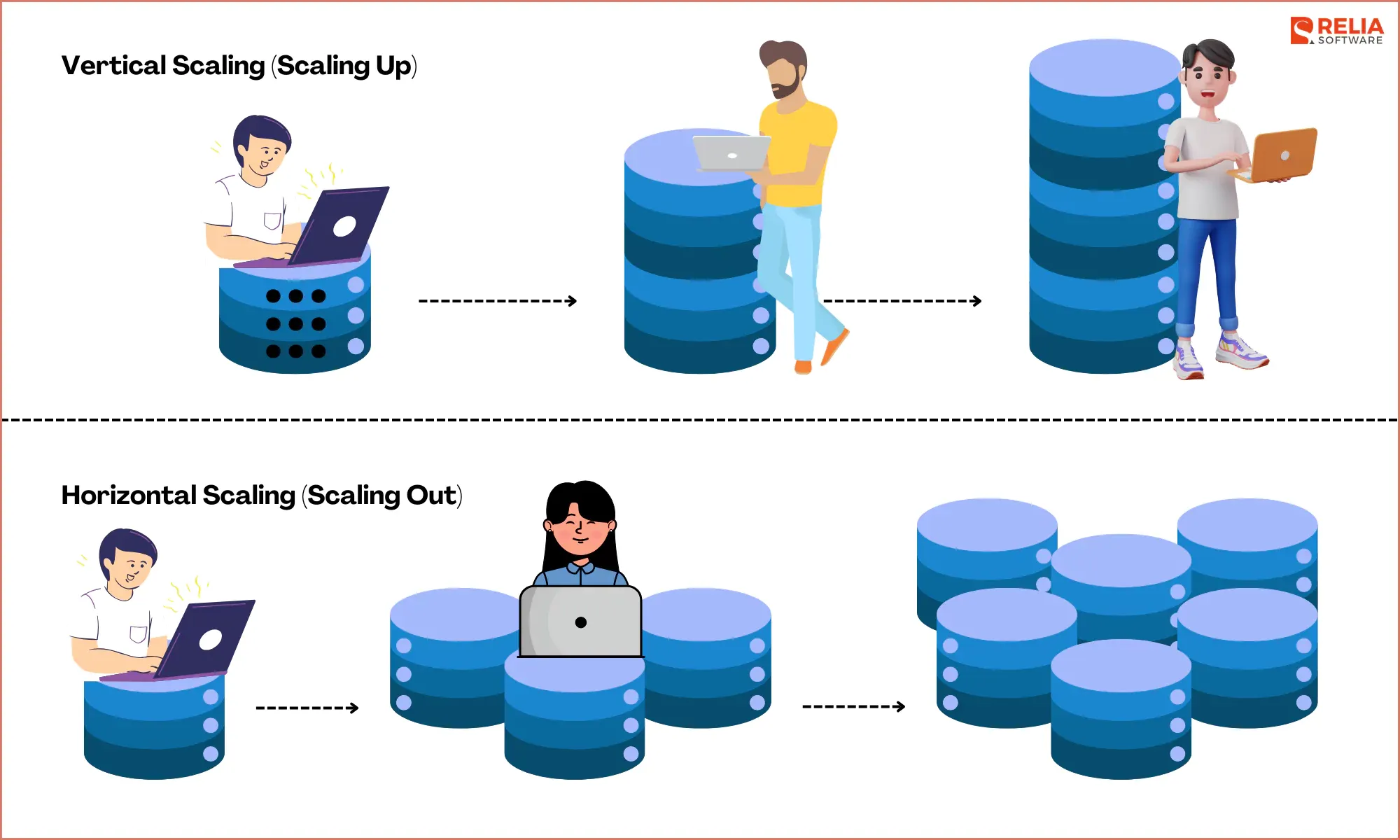
Vertical Scaling (Scaling Up)
Vertical scaling, also known as scaling up, involves enhancing an existing server by adding more resources such as CPU, RAM, or storage. This method is straightforward to implement since it primarily involves upgrading hardware or increasing instance sizes in cloud environments like AWS EC2, Google Cloud Compute Engine, or Azure Virtual Machines.
One of the key advantages of vertical scaling is its simplicity, as it avoids the complexities of distributed systems and requires minimal changes to the application architecture.
However, vertical scaling comes with limitations, such as:
- Finite Hardware Capacity: There's a limit to how much power you can add to a single server.
- Single Point of Failure: If the machine fails, the entire system could be affected.
- Cost: While vertical scaling can initially be cost-effective, upgrading hardware can become expensive, especially as needs grow.
- Downtime: Hardware upgrades may require downtime for implementation.
Horizontal Scaling (Scaling Out)
Horizontal scaling, also known as scaling out, involves adding more servers or nodes to an existing system to increase its capacity and performance.
This approach offers several benefits:
- Improved Fault Tolerance and Redundancy: The system can continue to operate even if one or more nodes fail.
- Handling High Traffic and Large Datasets: The workload can be distributed across multiple servers.
However, horizontal scaling also introduces some challenges:
- Increased Management Complexity: Requires effective coordination and communication between nodes.
- Distributed Database Management: Necessitates the use of distributed database management systems to ensure data consistency and integrity across multiple servers.
Examples of horizontal scaling include using multiple MySQL or PostgreSQL servers to distribute the load and enhance the system's overall performance and reliability.
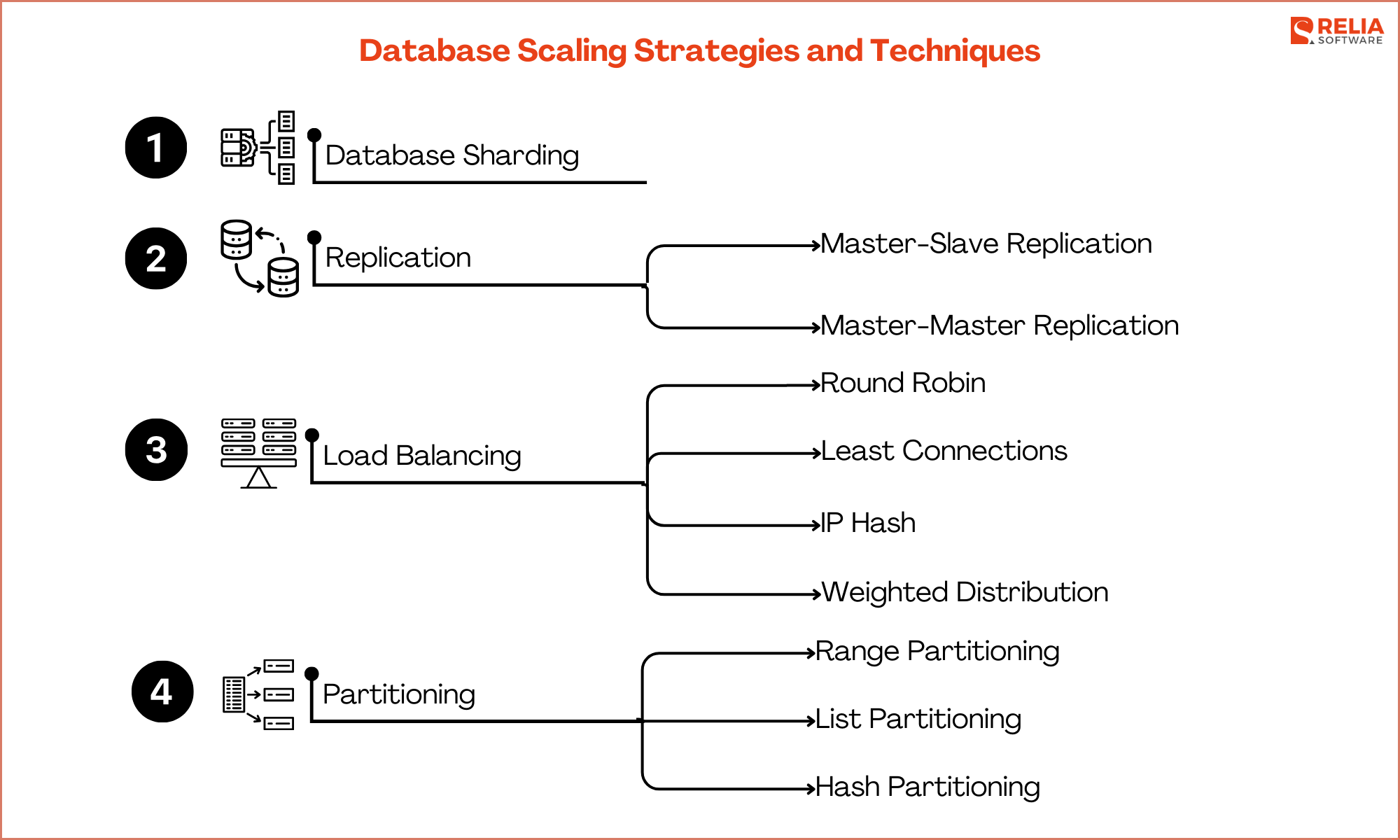
Database Scaling Strategies and Techniques
Database Sharding
Database sharding is a technique where a large database is divided into smaller, more manageable pieces called shards. Each shard operates as an independent database, containing a subset of the overall data.
This approach allows for improved performance and scalability, as queries can be processed in parallel across multiple shards, reducing the load on any single database instance. Sharding also enhances fault tolerance since the failure of one shard does not affect the availability of the others.
Sharding is particularly beneficial in scenarios involving large datasets and high transaction volumes, where a single database instance would struggle to handle the load efficiently.
For example, in SQL databases like MySQL and PostgreSQL, sharding can be used to distribute customer data across multiple shards based on geographic regions, ensuring that each shard only handles a portion of the total workload. This setup not only improves query performance but also simplifies maintenance and backup procedures by isolating data into smaller, more manageable segments.
Replication
Replication is a technique used to copy and maintain database objects, such as tables and records, across multiple database servers. This approach ensures data redundancy and improves availability, fault tolerance, and performance. There are two primary types of replication: master-slave and master-master.
- Master-Slave Replication
In master-slave replication, one database server (the master) handles all the write operations, while one or more additional servers (the slaves) handle read operations. The slaves continuously replicate data from the master, ensuring they have an up-to-date copy of the database. This configuration improves read performance by distributing the read load across multiple servers and provides a backup in case the master fails.
- Master-Master Replication
In master-master replication, two or more database servers act as both masters and handle both read and write operations. Each master replicates data to the other masters, ensuring data consistency across all servers. This configuration provides higher availability and fault tolerance, as any master can continue to operate even if another fails.
Load Balancing
Load balancing is essential for distributing incoming network traffic across multiple servers to ensure that no single server is overwhelmed. This approach optimizes resource utilization, maximizes throughput, minimizes response time, and ensures high availability and reliability of applications.
Importance of Distributing Traffic:
- Improved Performance: Load balancing ensures no single server is overburdened, leading to faster response times and enhanced overall performance.
- High Availability and Reliability: By redirecting traffic to other operational servers in case of a failure, load balancing ensures continuous service availability.
- Scalability: It supports horizontal scaling, allowing the addition of more servers to manage increasing traffic without significant changes to the application architecture.
- Efficient Resource Utilization: Ensures all servers operate at optimal capacity, preventing overuse or underuse of resources.
Techniques:
| Round Robin | Sequentially distributes client requests across a group of servers. |
| Least Connections | Directs traffic to the server with the fewest active connections, balancing the load more effectively under uneven traffic conditions. |
| IP Hash | Uses the client's IP address to determine which server handles the request, ensuring consistent client-server routing. |
| Weighted Distribution | Assigns more traffic to servers with higher capacities based on predefined weights. |
Tools:
| Tool | HAProxy | NGINX |
| Introduction | A high-performance, open-source load balancer supporting TCP and HTTP-based applications, known for its robustness, scalability, and extensive configuration options. | A widely-used web server that also functions as a reverse proxy, load balancer, and HTTP cache, known for its speed, flexibility, and ability to handle numerous concurrent connections. |
| Features | SSL termination, health checks, stickiness, detailed logging. | Load balancing for HTTP, TCP, and UDP, SSL termination, health checks, content caching. |
| Use Cases | Web applications, databases, microservices architectures. | Content delivery networks (CDNs), web applications, API gateways. |
Partitioning
Partitioning is a database optimization technique that divides a large database into smaller, more manageable pieces called partitions. Each partition can be managed and accessed separately, improving performance and maintainability.
3 Types of Partitioning:
| Range Partitioning | Divides data into partitions based on a range of values, such as dates. For example, a table of sales data can be partitioned by month. |
| List Partitioning | Distributes data based on a list of discrete values. For example, a table of customer data can be partitioned by region. |
| Hash Partitioning | Uses a hash function to assign data to partitions. This method evenly distributes data across partitions, which is useful for ensuring balanced workloads. |
Benefits and Challenges of Partitioning in SQL Databases:
- Benefits:
- Improved Query Performance: Queries can be executed more efficiently by scanning only relevant partitions instead of the entire table.
- Enhanced Manageability: Maintenance tasks such as backups, restores, and indexing can be performed on individual partitions, reducing downtime and resource usage.
- Scalability: Partitioning allows databases to scale horizontally by distributing partitions across multiple servers.
- Challenges:
- Complexity: Managing multiple partitions can be complex, requiring careful planning and administration.
- Query Optimization: Ensuring that queries are optimized to take advantage of partitioning can be challenging, requiring adjustments to indexing and query strategies.
- Data Distribution: Uneven data distribution across partitions can lead to performance bottlenecks, necessitating careful design and monitoring.
Both load balancing and partitioning are critical techniques for optimizing database performance, availability, and scalability. Load balancing distributes traffic efficiently across servers, while partitioning divides large datasets into manageable segments, each with its own set of benefits and challenges in SQL databases.
Database Scaling's Challenges and Solutions
Data consistency is a crucial aspect of database systems, ensuring that all users see the same data at the same time. Achieving consistency can be challenging, especially in distributed systems where data is stored across multiple nodes.
Understanding the CAP Theorem
The CAP theorem, also known as Brewer's theorem, states that in a distributed database system, it is impossible to simultaneously guarantee all three of the following properties:
- Consistency: Every read receives the most recent write or an error. In other words, all nodes see the same data at the same time.
- Availability: Every request (read or write) receives a response, whether it is successful or fails. The system remains operational 100% of the time.
- Partition Tolerance: The system continues to operate despite arbitrary partitioning due to network failures. This means that even if communication between some nodes is lost, the system as a whole continues to function.
According to the CAP theorem, a distributed system can only guarantee two out of the three properties at any given time. This leads to three possible design choices:
- CA (Consistency and Availability): The system is consistent and available as long as there is no network partition. Once a partition occurs, the system might fail to provide either consistency or availability.
- CP (Consistency and Partition Tolerance): The system remains consistent and tolerates network partitions, but availability might be compromised during a partition.
- AP (Availability and Partition Tolerance): The system remains available and tolerates network partitions, but it might not always be consistent.
Strategies for Maintaining Consistency
To maintain data consistency in distributed systems, several strategies can be employed:
| Strategy | Definition | Use Case |
| Two-Phase Commit (2PC) |
A protocol that ensures all nodes in a distributed system agree on a transaction's commit or rollback. It involves a coordinator node that sends a prepare message to all participating nodes and waits for a response before committing or aborting the transaction. | Suitable for financial transactions where consistency is critical. |
| Quorum-based Voting |
This approach requires a majority (quorum) of nodes to agree on a read or write operation. For example, in a system with 5 nodes, a write might require acknowledgment from 3 nodes before it is considered successful. | Often used in systems like Cassandra and Amazon DynamoDB, where a balance between consistency and availability is needed. |
| Eventual Consistency |
Guarantees that, given enough time, all replicas in a distributed system will converge to the same value. Writes are immediately available, but reads might initially reflect stale data until the system reaches consistency. |
Suitable for applications where immediate consistency is not critical, such as social media feeds or caching layers. |
| Strong Consistency | Ensures that a read always returns the most recent write. This approach typically requires synchronous replication and coordination across nodes, which can impact performance and availability. | Suitable for applications requiring immediate data accuracy, such as online banking or inventory systems. |
| Conflict Resolution | In systems that allow for temporary inconsistencies (like eventual consistency), conflict resolution mechanisms are necessary to reconcile differences. This can be achieved through strategies like last-write-wins, version vectors, or application-specific logic. | Used in distributed databases and systems where conflicts are expected and need to be resolved without human intervention. |
Maintenance and Management
Managing distributed systems can be complex due to their inherent characteristics, such as data distribution, network partitioning, and consistency requirements. Proper tools and best practices are essential to handle this complexity effectively.
Tools:
- Apache ZooKeeper (coordination);
- Consul (service discovery);
- Prometheus (monitoring);
- Kubernetes (container orchestration);
- Terraform (infrastructure as code).
Best Practices:
- Implement automated monitoring and alerts to track system performance and detect anomalies.
- Use configuration management tools like Ansible or Chef to ensure consistency.
- Perform regular backups and have a disaster recovery plan.
- Conduct scalability testing with tools like Apache JMeter.
- Maintain comprehensive documentation and regular training.
- Apply security measures such as encryption and access controls.
- Manage changes with version control systems like Git.
- Implement chaos engineering practices with tools like Chaos Monkey to further enhance the reliability and robustness of distributed systems.
These combined efforts help ensure that distributed systems operate efficiently, remain resilient to failures, and can scale effectively to meet increasing demands.
Final Thoughts
Vertical and horizontal scaling offer distinct advantages, with vertical scaling being ideal for predictable workloads and horizontal scaling excelling for high-traffic scenarios. Choosing the right scaling strategy is crucial for optimizing performance, cost, and manageability.
As database needs evolve, the future holds promise with distributed SQL solutions, serverless architectures, microservices combined with sharding, AI-powered optimization, and hybrid/multi-cloud strategies. These advancements pave the way for intelligent, automated, and adaptable database scaling, ensuring databases can seamlessly adapt to the ever-changing demands of modern applications.
>>> Follow and Contact Relia Software for more information!

- Mobile App Development
- Web application Development