In the face of increasing user demands, have you ever felt your Node.js application is a challenge? Single-threaded applications have limitations when faced with high traffic, leading to sluggish performance and bottlenecks. Fortunately, Node.js clustering emerges as a powerful technique to efficiently scale Node.js applications, unlocking the true potential of multi-core systems. Let's dive into the world of Node.js clustering and uncover its significance in modern web development.
>> Read more about Node.js-related topics:
- How to Dockerize A Node.js Application & Deploy it To EC2?
- A Comprehensive Guide for Node.js Dependency Injection
- How to Install Node.js on Ubuntu 22.04?
What is Node.js Clustering?
Node.js clustering is a technique used to scale Node.js applications by leveraging multiple CPU cores efficiently. It allows Node.js applications to utilize the full potential of multi-core systems, thereby improving performance and handling more concurrent requests.
Node.js clustering works by creating multiple child processes, also known as workers, to handle incoming requests. These workers are separate instances of the application running in parallel, each capable of processing requests independently. By distributing the workload across multiple workers, clustering enables applications to handle more traffic and improve responsiveness.
Utilizing Cluster Module - Your Gateway to Scalability
Node.js provides a built-in module called cluster to implement clustering functionality. The cluster module simplifies the process of creating and managing worker processes, abstracting away the complexity of inter-process communication.
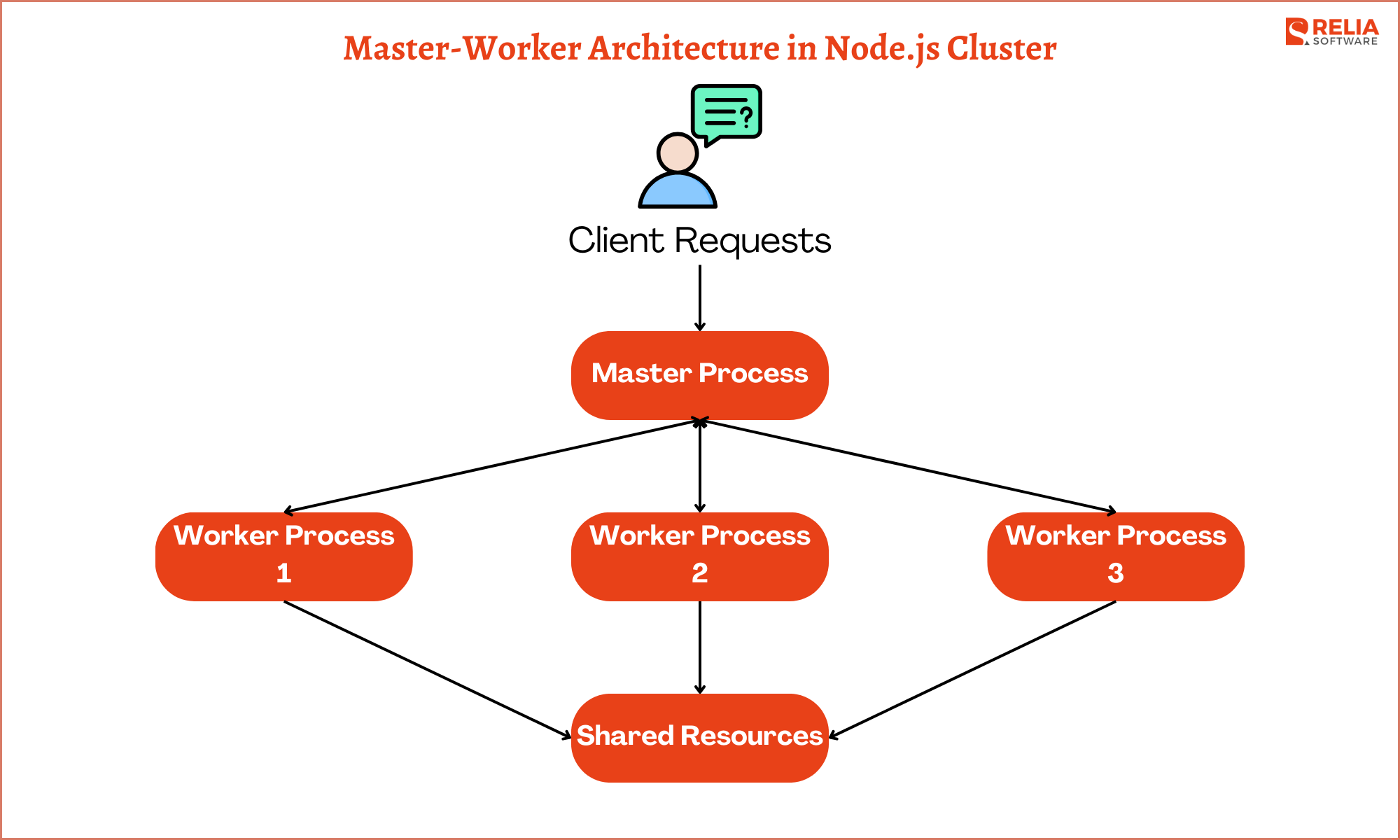
Master-Worker Architecture of Node.js Cluster
In a clustered Node.js application, there are two main components: the master process and the worker processes.
Master Process
The master process is responsible for spawning worker processes and distributing incoming connections among them. It listens for new connections and delegates them to the available workers using a round-robin algorithm or other load-balancing strategies. Additionally, the master process handles events related to worker management, such as worker termination or unexpected crashes.
>> Read more: Mastering Node.js Event Loop to Write Efficient Async Code
Worker Processes
Worker processes are instances of the Node.js application that handle incoming requests. Each worker runs the same application code independently, allowing them to operate in parallel. Worker processes communicate with the master process to coordinate tasks, such as sharing server ports and handling graceful shutdowns.
To sum up, the master process plays a crucial role in managing the lifecycle of worker processes. It monitors the health of worker processes and ensures that the application remains responsive and stable. If a worker process crashes or becomes unresponsive, the master process can restart it to maintain uninterrupted service.
Benefits of Node.js Clustering
Node.js clustering offers several compelling benefits for building scalable and reliable applications. Here are 3 typical ones:
Improved Performance
By distributing the workload across multiple CPU cores, clustering allows Node.js applications to handle more concurrent requests efficiently. This results in improved response times and better overall performance, especially under high traffic conditions.
Better Resource Utilization
Clustering enables Node.js applications to utilize the full capacity of multi-core systems. By running multiple worker processes in parallel, clustering maximizes CPU and memory resources, leading to optimal resource utilization and reduced bottlenecks.
Enhanced Reliability
Clustering enhances the reliability of Node.js applications by providing fault tolerance and resilience against failures. If a worker process crashes or becomes unresponsive, the master process can restart it automatically, ensuring uninterrupted service and mitigating the impact of potential failures.
Scenarios Where Node.js Clustering is Useful
After understanding why clustering is essential for Node.js applications, let's explore the 3 common scenarios where it proves to be particularly useful.
Handling Heavy Loads
Node.js clustering is particularly useful for handling heavy loads and scaling applications to accommodate a large number of concurrent users. By distributing the workload across multiple workers, clustering allows applications to scale horizontally and handle increasing traffic without sacrificing performance.
Maximizing CPU Utilization
In environments with multi-core systems, Node.js clustering maximizes CPU utilization by running multiple worker processes in parallel. This enables applications to make efficient use of available hardware resources and achieve higher throughput and responsiveness.
Achieving High Availability
Clustering plays a vital role in achieving high availability for Node.js applications. By running multiple instances of the application across different processes, clustering ensures that the application remains available even if individual components fail. This redundancy helps minimize downtime and ensures continuous availability for users.
Step-by-Step Guide for Implementing Node.js Clustering
Now that we've explored the benefits of Node.js clustering, let's dive into the practical implementation steps. This guide will walk you through the process of creating and managing worker processes effectively using the cluster module. We'll also provide code examples to illustrate each step.
Step 1: Initialize the Cluster Module
Start by requiring the cluster module and checking if the current process is the master process or a worker process.
const cluster = require('cluster');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
// Master process logic
console.log(`Master ${process.pid} is running`);
// Fork worker processes
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
// Listen for worker exit events
cluster.on('exit', (worker, code, signal) => {
console.log(`Worker ${worker.process.pid} died`);
// Restart the worker process
cluster.fork();
});
} else {
// Worker process logic
console.log(`Worker ${process.pid} started`);
// Your application logic here
}Step 2: Creating Worker Processes
In the master process, use the cluster.fork() method to create multiple worker processes. Each worker process runs the same application code independently.
Step 3: Handling Communication Between Master and Worker Processes
Use inter-process communication (IPC) to exchange messages between the master and worker processes. This allows the master process to delegate tasks to worker processes and coordinate their activities.
// Master process
cluster.on('message', (worker, message, handle) => {
console.log(`Message received from worker ${worker.process.pid}: ${message}`);
});
// Worker process
process.send('Hello from worker!');Step 4: Implementing Clustering with HTTP/HTTPS Servers
You can create HTTP or HTTPS servers within both master and worker processes. In a clustered environment, it's common to create servers only in worker processes to distribute incoming requests across multiple workers.
// Worker process
const http = require('http');
const server = http.createServer((req, res) => {
res.writeHead(200);
res.end('Hello, World!\n');
});
server.listen(8000);Finally, here is a complete code example:
const cluster = require('cluster');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`Worker ${worker.process.pid} died`);
cluster.fork();
});
} else {
console.log(`Worker ${process.pid} started`);
const http = require('http');
const server = http.createServer((req, res) => {
res.writeHead(200);
res.end('Hello, World!\n');
});
server.listen(8000);
}This is a basic implementation. For more complex scenarios, you might explore advanced topics like worker health monitoring, advanced communication strategies, and load balancing techniques.
By following this guide and utilizing the cluster module, you can effectively implement clustering in your Node.js application to take advantage of multi-core systems and achieve scalability and improved performance.
Best Practices and Tips for Mastering Node.js Clustering
Node.js clustering can significantly enhance the scalability and performance of your applications when implemented correctly. Here are some best practices and tips for effectively using Node.js clustering in real-world scenarios.
Scaling Strategies: Horizontal vs. Vertical Scaling
- Horizontal Scaling: Prefer horizontal scaling by adding more worker processes to distribute the workload across multiple CPU cores. Horizontal scaling allows your application to handle increased traffic by adding more instances, improving scalability and fault tolerance.
- Vertical Scaling: Consider vertical scaling by upgrading hardware resources (CPU, RAM) to handle increased load if horizontal scaling is not sufficient. However, vertical scaling has limitations compared to horizontal scaling in terms of scalability and cost-effectiveness.
Monitoring and Managing Worker Processes
- Monitoring: Implement monitoring solutions to keep track of worker processes' health, performance metrics, and resource utilization. Tools like PM2, New Relic, or Prometheus can help you monitor and manage your clustered application effectively.
- Automatic Restart: Set up automatic restart policies for worker processes to handle crashes or unexpected failures gracefully. Use features provided by the cluster module or external process managers to automatically restart failed worker processes.
>> Read more: Top 15 Application Monitoring Tools For Businesses
Handling Shared Resources and State
- Avoid Shared State: Minimize the use of shared resources and state between worker processes to prevent data inconsistencies and race conditions. Consider using in-memory caching solutions like Redis or distributed databases to manage shared state across multiple instances.
- Use Message Passing: Implement clear communication protocols and message passing mechanisms between master and worker processes using inter-process communication (IPC) or message queues. This helps maintain consistency and synchronization between worker processes.
By following these best practices and tips, you can effectively leverage Node.js clustering to build scalable, high-performance applications that can handle increased traffic and maintain reliability. Experiment with different scaling strategies, monitor your application's performance, and continuously optimize your clustering setup to meet the evolving needs of your application and users.
>> You may be interested in:
- Top 9 Best Node.js Frameworks For Web App Development
- Top 15 Node.js Projects for Beginners and Professionals
Conclusion
Node.js clustering has proven to be a valuable technique for building scalable, high-performance applications across various domains. By distributing workload across multiple CPU cores, clustering enables applications to handle increased traffic, improve responsiveness, and maintain reliability under demanding conditions. These real-world use cases demonstrate the versatility and effectiveness of Node.js clustering in addressing the scalability and performance requirements of modern web applications.
>>> Follow and Contact Relia Software for more information!

- development
- coding