Choosing the right database (SQL vs NoSQL) can help your app performs well, scales easily, and stays manageable. SQL databases are structured and reliable, ideal for complex queries. In contrast, NoSQL databases are flexible, scalable across servers, and handle large data efficiently.
Explore this article to discover which database type suits your app best and to understand the difference between SQL and NoSQL for an informed choice.
Key Differences between SQL and NoSQL
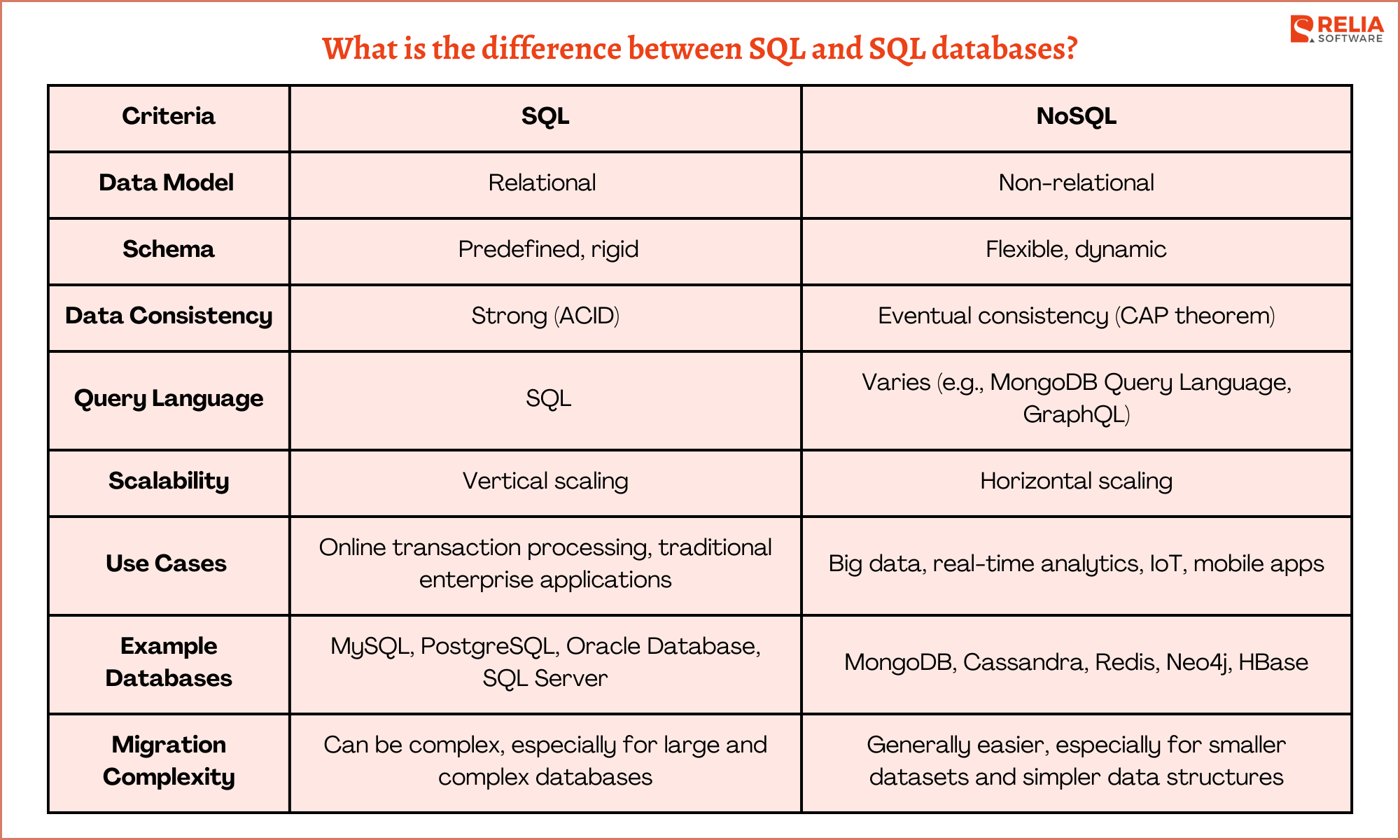
Architecture and Design
SQL:
- Normalization and Denormalization: SQL databases emphasize structured schemas, often relying on normalization to eliminate data redundancy and maintain integrity. While this improves data consistency, it can increase query complexity and slow down performance under high traffic. Denormalization, sometimes used to enhance read performance, balances redundancy for faster access, especially in analytics-heavy applications.
- Indexing Strategies: Indexes play a critical role in SQL, accelerating query execution by pre-sorting and optimizing data retrieval. However, excessive indexing can impact write performance, necessitating careful index management.
- Query Optimization and Data Integrity: SQL’s strict adherence to ACID principles enforces data integrity, even in high-traffic scenarios. Techniques like query caching, partitioning, and indexing help optimize performance, while triggers, constraints, and stored procedures enforce data quality and reliability.
NoSQL:
- Document-based, Key-Value, Column-Family, and Graph Databases: NoSQL databases vary significantly in structure. Document-based databases (e.g., MongoDB) allow semi-structured data storage and flexible schemas. Key-value stores (e.g., Redis) optimize for fast, simple retrieval, while column-family databases (e.g., Cassandra) are ideal for wide-column storage and analytics. Graph databases (e.g., Neo4j) excel in managing complex, interconnected relationships, useful in recommendation engines and social networks.
- Indexing, Sharding, and Replication: Unlike SQL, indexing strategies differ widely across NoSQL types, often trading some query performance for scalability. Sharding distributes data across nodes, enhancing scalability and resilience, particularly for high-throughput applications. Replication in NoSQL allows multiple copies of data, enhancing fault tolerance but requiring careful data sync management.
- Conflict Resolution in Distributed Systems: In distributed NoSQL architectures, maintaining data consistency across nodes is challenging. Eventual consistency models address this by syncing data over time, while conflict resolution strategies—such as last-write-wins or vector clocks—help manage discrepancies in high-availability systems, though they can result in temporary inconsistencies.
Data Consistency and Reliability Paradigms
SQL (ACID Properties)
SQL databases adhere strictly to ACID properties, essential for applications requiring reliable, precise data handling (e.g., banking, ERP, healthcare). Each ACID property ensures:
- Atomicity: Transactions are all-or-nothing; if one part fails, the entire transaction is rolled back.
- Consistency: Data integrity is maintained with rules (e.g., foreign keys, constraints) ensuring only valid data entries.
- Isolation: Manages concurrent transactions to avoid conflicts, using levels like Read Committed and Serializable.
- Durability: Completed transactions are permanently stored, protecting against unexpected failures through transaction logs.
NoSQL (CAP Theorem and BASE Model)
NoSQL databases often prioritize CAP Theorem principles, balancing these properties in distributed systems:
- Consistency: Ensures all nodes reflect the latest data, critical in scenarios needing up-to-date data (e.g., financial).
- Availability: Guarantees responses to every request, supporting high uptime for applications like e-commerce and IoT.
- Partition Tolerance: Maintains operations despite network issues, essential for distributed NoSQL systems across locations.
Many NoSQL systems prioritize availability over strict consistency, accepting slightly out-of-date data to ensure constant access, fitting high-scalability applications like social media feeds.
To address CAP constraints, many NoSQL databases adopt Eventual Consistency and BASE Model:
- Basically Available: Ensures high availability, even if data isn’t instantly current.
- Soft State: Allows temporary data inconsistency during updates.
- Eventual Consistency: Data synchronizes across nodes over time.
This approach is ideal for high-volume, distributed applications (e.g., social media, gaming, e-commerce), where minor lags in consistency are acceptable in exchange for continuous availability.
Database Scaling Approaches
SQL (Vertical Scaling):
SQL databases typically scale vertically by enhancing a single server's resources (e.g., CPU, memory, storage). This simplifies data management with a single data node, providing consistent query performance.
However, this approach becomes costly and limited as resources grow, eventually reaching hardware constraints. Vertical scaling is ideal for moderate workloads and read-heavy applications but is less suitable for very large datasets or high-throughput needs due to escalating costs.
NoSQL (Horizontal Scaling):
NoSQL databases scale horizontally by distributing data across multiple servers (nodes), allowing efficient handling of larger datasets and increased traffic. Adding standard hardware nodes is generally more affordable than upgrading a single high-spec server, making this approach cost-effective and flexible.
Horizontal scaling is optimal for large, distributed systems such as social media, IoT, and content delivery networks, supporting write-heavy and high-traffic applications with minimal impact on performance.
Data Distribution Techniques
SQL (Partitioning Techniques):
SQL databases use partitioning methods—such as range, list, and hash partitioning—to improve scalability and manage large tables within a single database instance. Partitioned tables divide data into smaller, manageable segments based on specific criteria (e.g., date ranges in range partitioning or key values in list partitioning).
This segmentation helps reduce the data scanned per query, optimizing performance on a single node. While effective, SQL partitioning does not enable full horizontal scaling across multiple servers but enhances query efficiency and load balancing within one server, particularly for analytics-heavy applications.
NoSQL (Sharding Techniques):
NoSQL databases employ sharding to distribute data across multiple servers, supporting high scalability in distributed environments. Common sharding methods include consistent hashing, which assigns data to nodes based on hash values, allowing even distribution and minimizing re-sharding when nodes are added or removed.
Range-based sharding organizes data by specific ranges (e.g., numeric or date), which is effective for applications querying data based on ranges. NoSQL’s sharding supports true horizontal scaling, distributing data across nodes to handle larger datasets and high traffic efficiently.
Data Locality and Query Efficiency in SQL and NoSQL:
Both SQL and NoSQL benefit from data locality, though the implementation differs.
- In SQL, partitioning optimizes data locality by keeping frequently accessed data within single-node segments, which reduces I/O loads and improves query speed, especially in large analytics tasks.
- In NoSQL’s distributed environments, data locality is key for minimizing latency and reducing cross-node communication. Techniques like multi-shard indexing and Read-Your-Writes consistency in NoSQL allow targeted queries that don’t require scanning the entire cluster, making queries faster in high-volume, distributed applications.
Performance and Query Optimization Techniques
SQL: SQL databases employ a range of strategies to improve query efficiency in complex, data-heavy applications:
- Index Tuning: Indexes are organized for quick data retrieval. While they significantly reduce query time, excessive indexing can slow down writes. Types of indexes include single-column indexes, multi-column (composite) indexes, and covering indexes, each suited to specific query types.
- Query Plan Analysis: SQL databases use query planners to evaluate and choose the most efficient execution path. Tools like
EXPLAINin PostgreSQL help identify bottlenecks, such as full table scans or inefficient joins, enabling targeted optimizations. - Materialized Views: Precomputed query results stored as tables allow for fast retrieval in repetitive, complex queries, especially useful in analytics and reporting. These views require periodic updates to reflect data changes, adding a maintenance cost.
NoSQL: NoSQL databases optimize differently due to their schema-less and distributed data nature:
- Indexing Strategies: NoSQL indexing varies based on data type and model. Document-based databases (e.g., MongoDB) use in-document indexes for faster reads. Unlike SQL, NoSQL indexing is designed with specific query patterns in mind to avoid slowing down writes.
- Secondary Indexing: Some NoSQL databases support secondary indexes on non-primary fields for complex queries, particularly in document and wide-column databases. These indexes improve query flexibility but can impact write speeds due to additional maintenance.
- Aggregations in Distributed Databases: Aggregation frameworks (e.g., MongoDB’s Aggregation Pipeline, Cassandra’s CQL aggregates) enable data transformations and analyses by distributing computations across nodes. This minimizes data movement and supports real-time performance in complex queries.
Benchmarking and Performance Metrics
Read and Write Latencies: SQL and NoSQL differ in latency characteristics:
- SQL databases prioritize transactional consistency, which can lead to higher write latency, especially with high concurrency, due to ACID compliance. Reads are optimized with indexing and query tuning for lower latency on frequent retrieval tasks.
- NoSQL databases often trade strict consistency for reduced latency. Document-based NoSQL (e.g., MongoDB) and in-memory caches (e.g., Redis) support faster reads. Write latency varies across NoSQL types; key-value stores (e.g., Cassandra) are designed for fast writes with eventual consistency, while others maintain slightly higher latencies to support indexing and replication.
Throughput: Throughput measures read and write capacity over time:
- SQL databases handle moderate throughput effectively but may slow under intensive writes due to locking and transaction management.
- NoSQL databases excel in high-throughput environments with frequent writes, such as social media and logging systems. Their distributed nature allows horizontal scaling to meet increased data demands.
Real-Time Analytics Performance: Real-time analytics capabilities vary by architecture:
- SQL databases support reliable analytics with ACID-compliant queries. However, schema rigidity and complex joins can limit speed in real-time environments.
- NoSQL databases are optimized for high-speed, unstructured data processing, making them well-suited for real-time applications like recommendation engines. Distributed analytics systems (e.g., MongoDB, Elasticsearch) support near-real-time querying by handling large datasets across nodes with minimal latency.
Security and Compliance Considerations
SQL:
- Transactional Security: SQL databases enforce robust security models to safeguard data within transactions. Using ACID-compliant transactions, SQL databases ensure consistent enforcement of security measures (e.g., read/write permissions) across multiple operations, essential for environments like banking and finance, where strict data accuracy and security are critical.
- Role-Based Access Control (RBAC): SQL databases offer granular access control, allowing administrators to assign specific privileges based on user roles. For example, a financial database may grant read-only access to certain roles while enabling data modification for authorized personnel. Advanced RBAC systems in platforms like Oracle and SQL Server limit access to sensitive data, reducing security risks.
- SQL Injection Prevention: SQL databases are commonly targeted by SQL injection attacks. Preventing these attacks involves using prepared statements and parameterized queries, which treat user input as data rather than executable code. Modern SQL databases (e.g., PostgreSQL, MySQL) implement safeguards against SQL injection through parameterized queries, effectively reducing unauthorized access risks.
>> Explore further: MySQL DDL: Statements, Atomic DDL, Online DDL, Algorithms
NoSQL:
- Role-Based Access Control (RBAC): NoSQL databases also implement RBAC to secure data access by user roles, though implementations may vary. For instance, MongoDB supports role-based privileges at the database and collection levels, beneficial for applications handling extensive datasets across multiple microservices. This fine-grained control helps limit access and manage permissions effectively.
- Encryption Strategies: Given that NoSQL databases often store data across distributed nodes, encryption is crucial. NoSQL systems support both encryption in transit (e.g., TLS) and at rest (e.g., AES-256), securing data even if physical servers or connections are compromised. Some systems, like AWS DynamoDB, provide default encryption at rest for sensitive data.
- Distributed Security Models: Many NoSQL databases use distributed security models to protect data across nodes and regions. Examples include secure clustering and node authentication in databases like Couchbase and Cassandra, with features like IP whitelisting to control node access within clusters.
- Compliance and Data Protection: NoSQL databases increasingly meet regulatory compliance (e.g., GDPR, HIPAA) through data privacy tools such as anonymization and masking. For instance, MongoDB Atlas supports GDPR's "right to be forgotten" by allowing document-level data deletion, essential for healthcare applications and IoT systems to protect patient data and adhere to HIPAA.
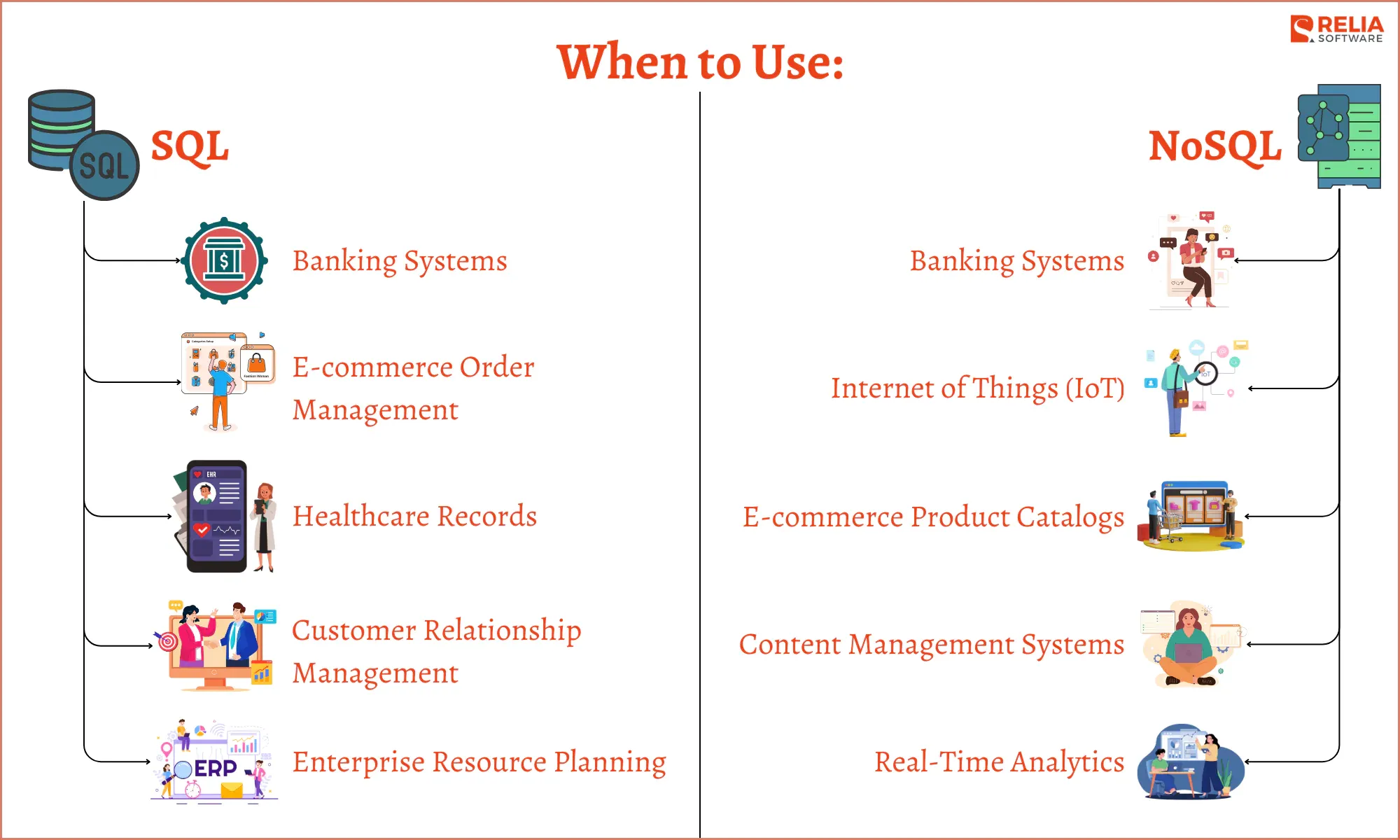
When to Use SQL Databases?
Use SQL for systems that need data consistency and integrity, structured data, complex queries, and smaller data volumes. Some specific use cases are:
- Banking Systems: SQL handles financial data reliably with ACID compliance, securing transactions and preventing double-spending.
- E-commerce Order Management: Robust relationships and constraints in SQL track inventory and payment securely in real-time.
- Healthcare Records: SQL’s structure and compliance support make it ideal for secure patient data storage.
- Customer Relationship Management (CRM): SQL links customer interactions for optimized, personalized services.
- Enterprise Resource Planning (ERP): SQL ensures data consistency across functions like finance and HR.
When to Use NoSQL Databases?
Use NoSQL databases for applications needing flexibility, scalability, and handling large volumes of unstructured data. Here are some cases:
- Social Media Platforms: Ideal for storing diverse, fast-changing user-generated content.
- Internet of Things (IoT): Suitable for managing vast, real-time sensor data streams.
- E-commerce Product Catalogs: Supports dynamic schemas for varying product types and attributes.
- Content Management Systems: Efficiently manages multimedia and varied data types.
- Real-Time Analytics: Handles large data inputs at scale, especially in fraud detection or monitoring user behavior.
Future of SQL and NoSQL: Hybrid Solutions
Hybrid Database Technologies
As data needs evolve, newer database technologies are combining SQL and NoSQL strengths. For example:
- Amazon Aurora: Supports MySQL and PostgreSQL compatibility, offering SQL-based functionality and flexible data structures for applications needing both transactional consistency and high-volume data handling.
- Microsoft Azure Cosmos DB: A multi-model database enabling SQL-like queries across various NoSQL models (document, key-value, graph, column-family), allowing adaptable storage and querying within one system.
- Google Cloud Spanner: Merges SQL's strong consistency with NoSQL's horizontal scalability, ideal for globally distributed applications needing reliable transaction consistency.
SQL-like Capabilities in NoSQL
The growing trend of enabling SQL-like queries on NoSQL databases makes NoSQL systems more accessible to SQL-experienced developers. Examples include:
- MongoDB: Supports SQL-like aggregation pipelines for complex queries.
- Cassandra: Introduced CQL (Cassandra Query Language), similar to SQL, for easy querying within its wide-column model.
- Apache Drill and Presto: Query engines enabling SQL queries over various NoSQL and distributed data sources, including MongoDB, HDFS, and Amazon S3. These tools offer a unified interface to query diverse datasets without transforming them into a strictly relational structure.
Unified Query Languages
As multi-model databases grow, unified query languages like SQL++ are emerging to bridge SQL and NoSQL. SQL++ offers advanced features for handling schema-less, nested, and hierarchical data, making it versatile across structured and semi-structured datasets.
This standardization supports both SQL and NoSQL paradigms, potentially enabling seamless transitions between structured and unstructured queries in a single database interface. With SQL++ and similar innovations, the future of data management promises enhanced flexibility and reduced complexity in handling diverse data formats.
Conclusion
In summary, SQL and NoSQL databases serve different use cases: SQL databases are optimal for structured data and transactional integrity, fitting applications in finance, healthcare, and ERP systems. Meanwhile, NoSQL’s flexibility and scalability excel with unstructured, high-velocity data in domains like IoT, social media, and real-time analytics.
Choosing between SQL and NoSQL should align with the application's data structure, scalability, and workload demands. Looking forward, the trend toward multi-model databases and unified query languages promises databases that can fluidly adapt, empowering agile, data-driven decision-making.
>>> Follow and Contact Relia Software for more information!

- development