In today's interconnected world, APIs (Application Programming Interfaces) have become the backbone of many applications, facilitating seamless data exchange between different systems. However, this reliance on APIs also introduces significant security vulnerabilities. This blog will explore key strategies to secure API servers, focusing on 6 common API vulnerabilities:
- Cross-Origin Resource Sharing (CORS)
- Error Disclosure
- Information Leak
- Insecure Cookies
- Path Traversal
- Rate Limiting
By understanding and implementing these security measures, you can enhance the security of your API servers and protect your applications and your users from potential threats.
Cross Origin Resource Sharing (CORS)
CORS is a set of browser controls set by web servers. It defines which domains (origins) are permitted to make requests using specific HTTP methods. As a result, a web server can allow users from a domain or block other users from another domain.
Why use CORS? If you have an API or web server with something to protect like user data, intellectual property and branding, CORS helps prevent unauthorized cross-origin access from untrusted sources.
How CORS works?
CORS is a browser-side mechanism. It does not prevent direct attacks from non-browser tools or scripts. This means if a malicious script or system directly attacks your API, it can ignore CORS entirely.
CORS works by instructing browsers on what is allowed. Browsers follow these rules, so users visiting a malicious site cannot silently interact with your protected API. In contrast, malicious bots or systems that don’t operate within a browser environment will ignore CORS altogether.
Some common situations:
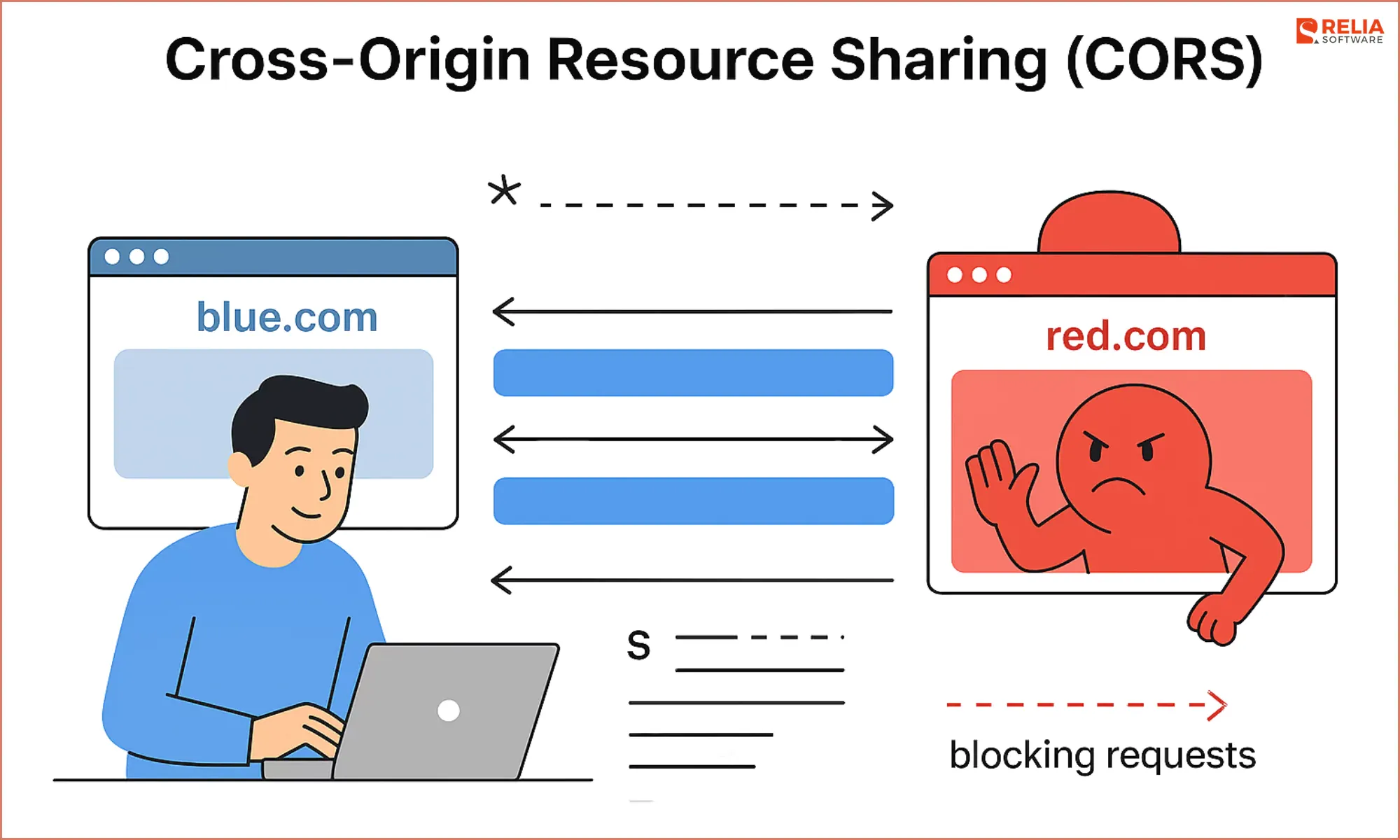
Imagine we have 2 web servers: blue.com that we are going to apply CORS configuration to protect itself and red.com that is a bad website.
red.comtries to embedblue.com(e.g., via an iframe):- If
blue.comsetsAccess-Control-Allow-Origin: *, it allows all domains (includingred.com) to make API calls. - If
blue.comsetsAccess-Control-Allow-Origin: blue.com, it restricts access, blocking requests fromred.com.
- If
blue.comembedsred.commaybe via a compromise.blue.comset CORS byCross-Origin-Resource-Policy: null: Users can accessred.comby just standing atblue.com. This can be the situation of malicious ads or third-party scripts.blue.comset CORS byCross-Origin-Resource-Policy: same-site: Users will not want to have a malicious element on their browsers, so we can immediately stop the compromise by this setting.
In summary, CORS doesn’t defend against all attack types. Instead, it’s a crucial layer in protecting browser-based interactions with your server by preventing unauthorized sites from accessing your API.
Error Disclosure
Error disclosure is when we have too much technical information in our error messages that are sent to users. This information can be valuable for malicious actors. They can take and use them to better understand how our system works and where its weaknesses may lie in order to attack it.
As a developer, it's important to note that:
- Erroring out is necessary for debugging when applications fail.
- Intentional error handling is good to prevent malicious actors.
- Developers and users need different error messages: Developers needs helpful information for logging and debugging, but users should only see simple, user-friendly messages without technical details.
The risk when we expose internal server errors is very bad. Attackers can know or easily guess the technology vulnerabilities on our servers like web framework, unauthorized URLs, SQL queries and other edge cases we haven't covered yet.
Error handling best practices:
DO | DO NOT |
|
|
Information Leak
An information leak occurs when a server unintentionally reveals details about its technology stack to users or external parties. This usually happens through response headers that are automatically included when a client (such as a browser or API client) makes a request. These headers are going to be beneficial for somebody to attack us by understanding what technology we are on.
Where does this happen?
Headers in HTTP responses can expose critical information, such as what framework, server, or platform your application is running on. These leaks are especially risky when interacting with external services, APIs, or even internal applications that are not properly configured.
How can we observe an information leak?
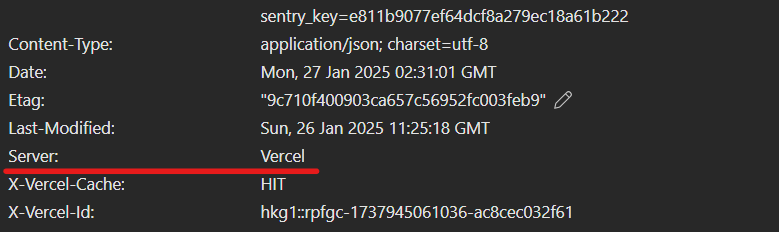
We can easily capture header information from a HTTP request by using Chrome Dev Tool to have a look at what actual information leak is.
Open a browser and access https://sentry.io/, then open Dev Tool. We can see lots of information in the header, but for me, I notice the “Server” header that has the value “Vercel”.
Let’s try to investigate what Vercel web server is, and further look for any of its available vulnerabilities. Vercel handles the entire deployment process, from building your Next.js code to deploying it to their servers. Based on the CVE Detail, we can find 18 vulnerabilities of Vercel. Some of them are:
- Denial of Service (DoS) via image optimization: Versions 10.x, 11.x, 12.x, 13.x, and 14.x (before 14.2.7) are vulnerable to a DoS condition in the image optimization feature, which can lead to high CPU consumption.
- Cache poisoning in server-side rendering: Attackers can craft a malicious HTTP request to poison the cache of a non-dynamic server-rendered route in the pages router.
That is exactly what attackers would do. They’d find out any useful clues to understand the server more. Therefore, our work should be hiding these unnecessary headers to prevent any risks for our servers. Besides, we also should consider which vulnerabilities of our technology stack to have corresponding strategies.
We can analyze our headers to ensure nothing causing information leak:
- Use a client to access the API (nothing cached).
- Headers will be returned in any HTTP client or programming language.
- Look for these headers:
Server,X-Powered-By,X-Version.
Some solutions for specific web server:
- Express.js: Install
helmetpackage to remove unnecessary headers. - Nginx: Set the flag
server_tokensoff.
By addressing these leaks, you reduce your server's exposure and make it more difficult for attackers to map out your system.
Insecure Cookies
Cookies are used to store data on a user’s device. Insecure cookies, however, are those that are created without proper access restrictions—making them readable by anyone who can intercept or access them.
When a cookie is created, it can be configured with certain security settings such as the Secure flag, the HttpOnly flag, and domain/path restrictions. These settings determine how and where the cookie can be accessed.
How is a cookie read and written?
Using Dev Tool, we can find some requests that are sending cookies in the Cookie header to the servers. They are keeping much information on our machines. In general, cookies are easily accessed and modified, so we would want to protect them from being used by anybody maliciously.
Cookies are stored as key-value pairs. These values can have data types like boolean, number, UUID, base-64 encoded token. If someone changes the values of cookies when requesting the servers, they can guess the behaviors for each cookie value and see how it works in order to influence the servers.
Besides, servers can add new key-value pairs to cookies by using the Set-Cookie header. Set-Cookie should have some important data to secure the cookies like Secure and HttpOnly. These settings will define the locations that are allowed to request the cookie.
>> Explore: Implementing Golang Authentication with JWT (JSON Web Tokens)
Cookie Decoding
Cookie data is relatively easy to access on a device. Therefore, we should avoid storing any sensitive or unnecessary information in cookies. It’s important to regularly review your cookies and evaluate whether the data stored there is appropriate.
First of all, when we have a cookie set, we tend to find out some interesting keys such as user_id, session_id, or user_role. It’s worth testing different values for these keys to see how the server responds. Ideally, the server should handle all unexpected or altered cookie values safely.
Second, we will sort data types of cookie values:
- Unique ID Strings: These are harder to interpret but can be tracked and analyzed.
- Numeric IDs: Try increasing or decreasing the value to observe changes.
- Booleans: Switch between true and false to test outcomes.
- Encoded Data: These should be treated as untrusted input. Try modifying them to see if the server handles them securely.
Cookie Problems:
- Cookie forging / Fuzzing (Trusting cookie data): If we change the cookie value sent to the server, we can access something that we are actually not allowed or something we do not intend to access. That is by the server trusting the cookie data.
- Data Harvesting (
HttpOnlyFlag): If a cookie is setHttpOnlyflag, it‘s not going to be read from JavaScript (client-side script). So, the cookie is only read by HTTP requests without being accessed in the middle of our transactions. - Data Harvesting in Transit (
SecureFlag): Secure flag makes browsers have to encrypt the cookie on its transport, so something in the middle cannot read in plain text.
Solutions:
- Treat cookies as untrusted user data.
- Be restrictive on what data is stored in cookies.
- Analyze our cookies from an offensive mindset.

Path Traversal
Path traversal vulnerabilities occur when a user or attacker is able to access files or directories on a server that were never meant to be exposed. This can involve direct file access within or outside the web root directory, or access to files that shouldn’t be reachable. This often dues to insecure dynamic file inclusion or weak server logic.
There are a number of ways that path traversal vulnerabilities can be created, such as:
- Missing server configuration
- Lack of defensive coding
- Vulnerabilities in the API specification
Examples
One common scenario is when a developer allows a user to provide a filename, which is then used to dynamically include a file. If not properly validated, the attacker might exploit this to access sensitive files like configuration files or system files.
Another example is when a user is allowed to input a directory name, and the server uses this to access files in that directory. Without validation, the attacker could manipulate the input to browse directories and access private or sensitive data.
These vulnerabilities can be exploited in multiple ways:
- Stealing sensitive data
- Gaining unauthorized access to the server
- Launching denial-of-service (DoS) attacks
The solutions to prevent Path Traversal vulnerabilities are:
- Validating user input: This involves checking that the user input is in the expected format and does not contain any malicious characters. For example, you can use a regular expression to check.
- Using a whitelist of allowed file names and directories: This involves creating a list of allowed file names and directories and only allowing the user to access files and directories that are on the list.
- Escaping special characters in user input: This involves escaping any special characters in the user input that could be used to exploit a path traversal vulnerability. For example, you can escape the following characters:
.(dot)/(forward slash)\(backslash)..(double dot)
- Using a secure file system: This involves using a file system that is configured to prevent path traversal vulnerabilities. For example, you can use a file system that does not allow users to access files outside of their own home directory.
Rate Limiting
Rate limiting is a technique used to control the number of requests that can be made to an API within a given time period. This is important for a number of reasons, including:
- Preventing denial of service attacks: Attackers can use bots to send a large number of requests to an API, which can overwhelm the server and make it unavailable for a while. Rate limiting can help to prevent this by limiting the number of requests that can be made from a single IP address or user.
- Improving performance: Rate limiting can help to improve the performance of an API by preventing it from being overloaded with requests. This can free up resources for other tasks.
- Reducing costs: Rate limiting can help to reduce the costs of running an API by reducing the amount of traffic that needs to be processed. This can be especially important for APIs that are hosted on cloud platforms.
How can we implement Rate Limiting:
- Using a third-party service: There are a number of third-party services that can be used to rate limit API traffic. These services can be easily integrated into most APIs and can provide a variety of features, such as custom rate limits and IP-based rate limiting.
- Using a middleware: Middleware is software that sits between the API and the server. Middleware can be used to rate limit API traffic by inspecting incoming requests and blocking requests that exceed the rate limit.
We also need to consider
- The rate limit: The rate limit is the maximum number of requests that can be made within a given time period. The rate limit should be set based on the expected traffic for the API.
- The time window: The time window is the period of time over which the rate limit is applied. The time window should be set based on the expected traffic patterns for the API.
- The enforcement mechanism: The enforcement mechanism is the method used to enforce the rate limit. This could be done by blocking requests that exceed the rate limit, or by returning an error message to the client.
>> Read more:
- Top 12 API Testing Tools for Software Testing Process
- The Guideline To Become Skilled API Developer
Conclusion
By addressing these API security vulnerabilities and implementing a multi-layered security approach, we can build robust and secure APIs that are resistant to common attacks and provide a safe and reliable experience for our users.
>>> Follow and Contact Relia Software for more information!

- development
- coding