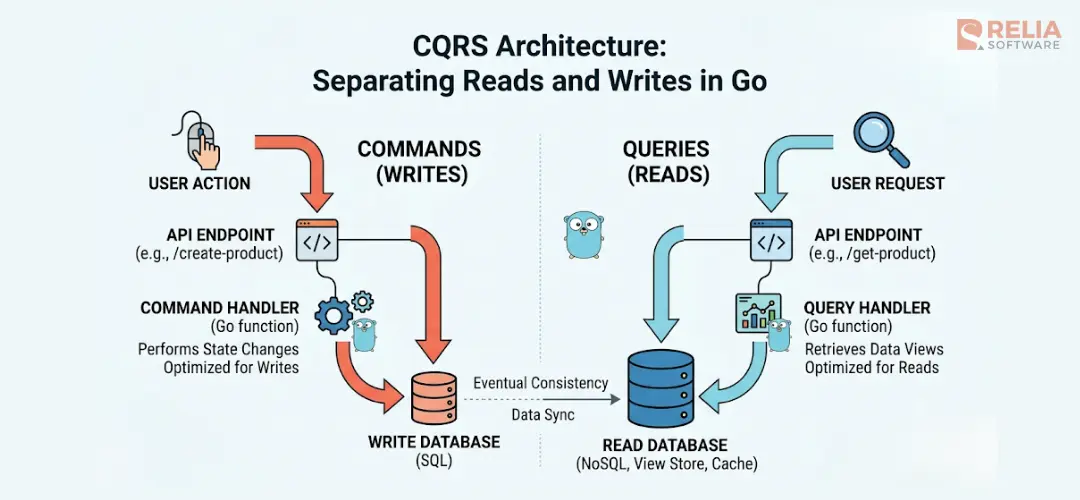
When building web services in Go, reusing a single struct to handle both incoming data updates and outgoing user interface displays creates structural friction. Write operations require strict business validation and database integrity, while read operations need flat, fast, and pre-joined data for the UI. Forcing one model to do both jobs results in slow database queries, fragile code, and high maintenance overhead.
Command Query Responsibility Segregation (CQRS) solves this data-handling conflict by splitting your application into two completely independent paths: a write-optimized model for commands, and a read-optimized model for queries.
This article walks you through a practical guide on implementing CQRS in Go. We will cover an framework-free folder structure, clean command and query dispatchers, and the real-world trade-offs you need to consider before adding this pattern to your architecture.
How Coupling Reads and Writes Degrades Go Performance?
In a recent project, I maintained a product catalog service that handled roughly 50 read requests for every single write. The domain model, a single Product struct, served both: it carried validation logic for writes, computed fields for display, and permission guards for updates.
Over time, query handlers accumulated read-specific joins and denormalized fields that had no place on the write side. Every change required touching the same model, the same repository layer, the same test suite.
The symptoms were subtle at first: slow query performance because the ORM was eager-loading associations the write path needed but reads did not. Then came the bigger problem: developers adding fields for display purposes that silently influenced write validation.
The model became load-bearing in two directions at once, and no amount of careful refactoring on a shared structure fixed that.
What I needed was CQRS in Go — a pattern that draws a hard boundary between the read and write models.
What Is the CQRS Pattern?
CQRS, or Query Responsibility Segregation, is an architectural pattern that splits data operations into two distinct models: commands that change state, and queries that read state.
The term comes from Bertrand Meyer's command-query separation principle, scaled up to the service level. In practice, the write side handles validation, business rules, and persistence. The read side optimizes for how data is consumed, flat, denormalized, fast. Neither side knows the other's shape.
Commands vs. Queries: Key Differences
| Dimension | Command | Query |
| Purpose | Mutate state | Return data |
| Return Value | Error or ID | DTO / projection |
| Validation | Domain rules | Input sanitization only |
| Model Used | Domain entity | Read-optimized struct |
| Side Effects | Yes | None |
Prerequisites
Before implementing CQRS in Go, you should be comfortable with Go interfaces and how they enable dependency injection, the repository pattern as a data access abstraction, and basic domain modeling, separating your entity from its persistence concern.
Familiarity with struct embedding and clean type definitions helps when building the read DTO layer. If you can write a clean repository interface and inject it into a handler, you are ready.
How to Implement CQRS in Go?
The key insight when you implement CQRS in Go is that Go's interface system makes the dispatcher pattern clean without a framework.
Domain Structure
A folder layout that makes the separation visible forces discipline on contributors.
internal/
product/
command/
create_product.go # command struct + handler
update_product.go
query/
get_product.go # query struct + handler
list_products.go
domain/
product.go # write-side entity
dto/
product_view.go # read-side projection
dispatcher.goIn the code above, command/ and query/ are sibling packages with no import dependency between them. The domain/ package belongs only to the command side, while dto/ belongs to the query side. This layout makes it structurally impossible for a read handler to mutate domain state.
Building the Command Side (Write Model)
The command handler owns all write logic: validation, domain construction, and persistence. Here is a minimal CreateProductCommand with its handler.
// command/create_product.go
type CreateProductCommand struct {
Name string
Price float64
Category string
}
type CreateProductHandler struct {
repo domain.ProductRepository
}
func NewCreateProductHandler(repo domain.ProductRepository) *CreateProductHandler {
return &CreateProductHandler{repo: repo}
}
func (h *CreateProductHandler) Handle(ctx context.Context, cmd CreateProductCommand) (string, error) {
p, err := domain.NewProduct(cmd.Name, cmd.Price, cmd.Category)
if err != nil {
return "", fmt.Errorf("invalid product: %w", err)
}
if err := h.repo.Save(ctx, p); err != nil {
return "", fmt.Errorf("save failed: %w", err)
}
return p.ID, nil
}In the code above, the handler receives a plain command struct without HTTP context and ORM model. domain.NewProduct enforces business rules like price validation and required fields, so the handler stays thin. Returning the new ID gives the caller enough to proceed without exposing the full domain entity.
Building the Query Side (Read Model)
The query handler returns a read-optimized DTO. It bypasses the domain model entirely and hits a read store or a denormalized view.
// query/get_product.go
type GetProductQuery struct {
ProductID string
}
type ProductView struct {
ID string
Name string
Price float64
CategoryName string // denormalized — no join needed at read time
InStock bool
}
type GetProductHandler struct {
readDB ReadDB
}
func (h *GetProductHandler) Handle(ctx context.Context, q GetProductQuery) (*ProductView, error) {
return h.readDB.FindProductView(ctx, q.ProductID)
}In the code above, ProductView carries CategoryName as a denormalized string rather than a foreign key. This means the read model shapes data for the consumer, not for normalization.
ReadDB is an interface pointing at whatever store is optimized for reads, whether that is a materialized view, a read replica, or a cache. The handler itself is deliberately trivial.
Wiring It Together with a Clean Command/Query Dispatcher
A simple dispatcher routes commands and queries to their handlers without Golang reflection or a heavy framework.
// dispatcher.go
type CommandDispatcher struct {
createProduct *command.CreateProductHandler
updateProduct *command.UpdateProductHandler
}
func (d *CommandDispatcher) Dispatch(ctx context.Context, cmd any) (any, error) {
switch c := cmd.(type) {
case command.CreateProductCommand:
return d.createProduct.Handle(ctx, c)
case command.UpdateProductCommand:
return d.updateProduct.Handle(ctx, c)
default:
return nil, fmt.Errorf("unknown command type: %T", cmd)
}
}
type QueryDispatcher struct {
getProduct *query.GetProductHandler
listProduct *query.ListProductsHandler
}
func (d *QueryDispatcher) Dispatch(ctx context.Context, q any) (any, error) {
switch qr := q.(type) {
case query.GetProductQuery:
return d.getProduct.Handle(ctx, qr)
case query.ListProductsQuery:
return d.listProduct.Handle(ctx, qr)
default:
return nil, fmt.Errorf("unknown query type: %T", q)
}
}In the code above, I use two separate dispatchers instead of one unified bus, which is intentional. Mixing command and query routing into a single dispatcher obscures the boundary I am trying to enforce.
The type switch is verbose but explicit; for larger handler counts, you can define a CommandHandler[C, R] generic interface in Go 1.18+.
Integrating Dispatchers with HTTP Handlers
Here is how the dispatcher integrates with a typical HTTP layer
// api/product_handler.go
func (h *ProductAPI) CreateProduct(w http.ResponseWriter, r *http.Request) {
var req CreateProductRequest
if err := json.NewDecoder(r.Body).Decode(&req); err != nil {
http.Error(w, "invalid request body", http.StatusBadRequest)
return
}
cmd := command.CreateProductCommand{
Name: req.Name,
Price: req.Price,
Category: req.Category,
}
result, err := h.commandDispatcher.Dispatch(r.Context(), cmd)
if err != nil {
http.Error(w, err.Error(), http.StatusUnprocessableEntity)
return
}
w.Header().Set("Content-Type", "application/json")
json.NewEncoder(w).Encode(map[string]string{"id": result.(string)})
}
func (h *ProductAPI) GetProduct(w http.ResponseWriter, r *http.Request) {
productID := chi.URLParam(r, "id")
q := query.GetProductQuery{ProductID: productID}
result, err := h.queryDispatcher.Dispatch(r.Context(), q)
if err != nil {
http.Error(w, "product not found", http.StatusNotFound)
return
}
w.Header().Set("Content-Type", "application/json")
json.NewEncoder(w).Encode(result)
}The HTTP handler stays very thin because its only job is I/O translation. It simply decodes the JSON request, builds the command or query struct, dispatches it, and returns the response.
All actual business logic lives inside the command or query handlers, keeping the API layer completely separate. The type assertion result.(string) is a simple trade-off required because the dispatcher uses the flexible any type in its signature.
When NOT to Use CQRS in Go?
Go CQRS architecture is not free. It introduces immediate complexity because you must maintain parallel models, separate handler layers, and often entirely distinct data stores.
You should skip the CQRS pattern if your system meets any of the following criteria:
- Your application is a simple CRUD service: If there is no meaningful difference between how you write data and how users read it, managing duplicate models adds zero value.
- Your team size or development velocity is constrained: Maintaining parallel read and write models creates overhead that can slow down small teams more than it helps.
- Your application handles low traffic volume: When traffic is minimal, a single optimized database query can easily handle both reads and writes without performance degradation.
- Your system cannot tolerate eventual consistency: When data propagates to the read store asynchronously, it introduces hard-to-debug lag. If your UI breaks because a user creates a product but cannot see it in their dashboard immediately, CQRS is not the right choice.
>> Read more: A Detailed Guide to ACID Properties in DBMS with Examples
In my experience, CQRS earns its architectural weight only at scale such as a 50:1 read/write ratio, distinct read-caching strategies, or audit trails that require event sourcing. Below that threshold, a well-structured, single model is almost always the better call.
Code Comparison: Bad Practices vs. Good Practice
Anti-pattern: Sharing Structs Between Read and Write Paths
Reusing the domain entity directly as both the write model and the API response is the most common mistake when teams first encounter CQRS Golang implementation. Go
// One struct doing two jobs
type Product struct {
ID string
Name string
Price float64
CategoryID string // write side needs FK for validation
Category *Category // read side eager-loads this — ORM couples both paths
CreatedBy string // internal audit field leaks into API response
DeletedAt *time.Time // soft-delete flag has no business in a read DTO
}
// Handler returns domain entity directly — read and write coupled
func (h *Handler) GetProduct(ctx context.Context, id string) (*Product, error) {
return h.repo.FindByID(ctx, id)
}In the code above, Category is an eager-loaded association the ORM fetches on every read, even when the caller only needs the name string. DeletedAt and CreatedBy are internal fields that now leak into every API consumer. Any change to write-side validation requirements forces a change to the struct that every read path depends on.
Best Practice: Distinct Domain Models and Read Projections
// Write-side domain entity — internal, never serialized directly
type Product struct {
id string
name string
price float64
categoryID string
deletedAt *time.Time
}
func NewProduct(name string, price float64, categoryID string) (*Product, error) {
if price <= 0 {
return nil, errors.New("price must be positive")
}
return &Product{
id: uuid.New().String(),
name: name,
price: price,
categoryID: categoryID,
}, nil
}
// Read-side projection — shaped for consumers, not for ORM
type ProductView struct {
ID string `json:"id"`
Name string `json:"name"`
Price float64 `json:"price"`
CategoryName string `json:"category_name"` // denormalized at write time
}
// Read handler hits a separate read store
func (h *GetProductHandler) Handle(ctx context.Context, q GetProductQuery) (*ProductView, error) {
return h.readStore.FindView(ctx, q.ProductID)
}The Product domain entity uses unexported (lowercase) fields by design, making it completely impossible to serialize directly into JSON or leak into API responses.
The ProductView struct carries only the specific data fields that API consumers need. By denormalizing fields like CategoryName directly into the struct, the read path bypasses expensive database joins entirely.
The read-side packages and handlers never import the domain package. This strict rule ensures that the boundary between reads and writes is enforced automatically by the Go compiler, completely preventing accidental domain state mutations on the query side.
Common Pitfalls to Avoid in Go Microservices
Over-engineering early: Do not use CQRS for low-traffic services processing only a few hundred requests a day. The complexity cost is immediate, but the performance benefits remain entirely theoretical. Only introduce CQRS when you have a measurable performance or code complexity issue.
Ignoring UI lag: Asynchronous read stores cause data delay. The frontend must explicitly handle this stale data using loading states or optimistic UI updates. Assuming reads are always fresh creates hard-to-reproduce bugs.
Sharing the database tables: Using the same database tables and ORM models for both sides eliminates the benefits of CQRS. The read store must use a separate materialized view, a dedicated read replica, or a cache populated by the write path.
Premature event sourcing: CQRS and event sourcing are independent patterns. Adding event sourcing before your team understands how to rebuild projections or migrate event schemas creates massive maintenance debt.
>> Read more: Top 10 Microservices Design Patterns Developers Should Know
Conclusion
CQRS is a powerful tool when the problem it solves like read/write asymmetry, model complexity, independent scaling is actually present in your system. What makes it worth adopting in Go specifically is that the language's interface system and package boundaries let you enforce the separation structurally rather than by convention alone.
That said, the pattern carries real costs: two models to maintain, eventual consistency to reason about, and onboarding complexity for new contributors. The goal is not to implement CQRS in Go because it is architecturally beautiful, but because a concrete problem in your service demands the boundary it creates.
Hope this blog can help you in your Golang technical path!
>> Follow and contact Relia Software for more information!

- golang
- coding